

Przetwarzanie strumieniowe jest dzisiaj standardem. Skoro i tak większość osób korzysta z Apache Kafka jako kolejki, czemu nie spróbować Kafka Streams? Jest to rozwiązanie skalowalne i nie wymaga specjalnych środowisk typu YARN czy Apache Mesos. Ten wpis rozpoczyna serię wpisów dotyczących Kafka Streams.
Rozkład jazdy
- Kafka Streams 101 – de/serilizacja ✔
- Kafka Streams 102 – Wyjątki i Dead Letter Queue
- Kafka Streams 103 – Pisz testy, zapomnij o Kafce
- Kafka Streams 201 – Obliczanie prędkości, Processor API, KeyValueStore
Cel
We wpisach z tego cyklu będę bawił się Kafka Streams, by poznać możliwości tej technologii. Docelowo chcę napisać program/y w Kafka Streams, który będzie:
- Wzbogacał strumień lokalizacji pojazdów ZTM w Warszawie w prędkość i wektor poruszania się
- Filtrował błędne odczyty
- <tutaj myślę o agregacjach, ale jeszcze nie wiem jakich 🙂 >
- Myślałem też o wykrywaniu czy autobus znajduje się na przystanku
Zobaczymy, co z tego wyjdzie. Nabieram doświadczenia, wiec jak masz jakiś pomysł lub uwagi, nie krępuj się :-).
Czy musimy sprawdzać wiarygodność pobieranych danych? ? Jak widać tak. Pojazd linii 178 nagle teleportował się na Ursynów ? #elasticsearch #elasticstack pic.twitter.com/M1gYhh9ZaJ
— Maciej Szymczyk (@maciej_szymczyk) February 5, 2020
Rozkład jazdy
- Kafka Streams 101 – de/serilizacja ✔
- Kafka Streams 102 – Wyjątki i Dead Letter Queue
- Kafka Streams 102 – Pisz testy, zapomnij o Kafce
Podstawy
Kafka Streams to program napisany w Javie, który jest jednocześnie konsumentem i producentem Kafki. Źródło wejściowe i wyjściowe to oddzielne topic-i w Apache Kafka. Bardzo fajnie mówił o tym temacie Radek z Big Data Passion na Confiturze, tutaj link do YouTube.
Środowisko
Wykorzystałem docker-compose od bitnami, o którym wspominałem we wpisie o Dockerze. Dodałem do niego Kafdrop, bo tak.
version: '2'
services:
kafdrop:
image: obsidiandynamics/kafdrop
restart: "no"
ports:
- "9000:9000"
environment:
KAFKA_BROKERCONNECT: "kafka:9092"
JVM_OPTS: "-Xms16M -Xmx48M -Xss180K -XX:-TieredCompilation -XX:+UseStringDeduplication -noverify"
depends_on:
- kafka
zookeeper:
image: 'bitnami/zookeeper:3'
ports:
- '2181:2181'
volumes:
- 'zookeeper_data:/bitnami'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: 'bitnami/kafka:2'
ports:
- '9092:9092'
- '29092:29092'
volumes:
- 'kafka_data:/bitnami'
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,PLAINTEXT_HOST://:29092
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
depends_on:
- zookeeper
volumes:
zookeeper_data:
driver: local
kafka_data:
driver: local
Kafdrop pozwala m.in wyklikać nowy topic. Kafka jest co prawda w dockerze i można się tam dostać docker exec -it <kontener> bash, ale ja ściągnąłem Kafkę, by móc wykonywać operacje z terminala na mojej maszynie. Poniżej kilka komend, które mogą Ci się przydać.
# Utworzenie nowego topic-a
bin/kafka-topics.sh --create --bootstrap-server localhost:29092 --replication-factor 1 --partitions 1 --topic wiaderko-input
#Wyświetlenie listy topic-ów
bin/kafka-topics.sh --list --bootstrap-server localhost:29092
#Uruchomienie producenta w konsoli - key:value
bin/kafka-console-producer.sh --broker-list localhost:29092 --topic wiaderko-input --property "parse.key=true" --property "key.separator=:"
#Uruchomienie konsumenta w konsoli
bin/kafka-console-consumer.sh --bootstrap-server localhost:29092 --topic wiaderko-output \
--from-beginning --formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true --property print.value=true \
--property key.deserialzer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
#Zmiana konfiguracji topic-a, tutaj zmiana retencji na 5 sekund
bin/kafka-topics.sh --zookeeper localhost:2181 localhost:29092 --alter --topic wiaderko-input --config retention.ms=5000
Pierwszy strumień – LowerCaseStream
Pierwsze koty za płoty. Na razie nic wyszukanego. Przychodząca wartość będzie zmieniana na małe litery.
public class LowercaseStream {
public static final String INPUT_TOPIC = "wiaderko-input";
public static final String OUTPUT_TOPIC = "wiaderko-output";
public static void main(String[] args) throws Exception {
Properties props = createProperties();
final StreamsBuilder builder = new StreamsBuilder();builder.<String, String>stream(INPUT_TOPIC)
.mapValues(v -> v.toLowerCase())
.to(OUTPUT_TOPIC, Produced.with(Serdes.String(), Serdes.String()));
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
}
private static Properties createProperties() {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wiaderko-lowercase-stream");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return props;
}
}
- Najpierw musimy skonfigurować strumień (linia 7).
- “Mięsko”, czyli to jak strumień ma działać, znajduje się w liniach 9-1q. Wykonywana jest metoda mapValues i strumień kierowany jest do innego topic-a.
- Metodę peek wykorzystałem do zerknięcia w strumień w celach demonstracjnych. Peek używa się do bezstanowych operacji na rekordach.
- Linie 13-33 jest to utworzenie topologii, strumienia i obsłużenie jego zamknięcia.
W Intellij wystarczy odpalić dany plik. Jeśli zbudowałeś/aś JAR-a to odpalisz go komendą:
java -cp wiadrodanych-kafka-streams.jar wiadrodanych.streams.LowercaseStream
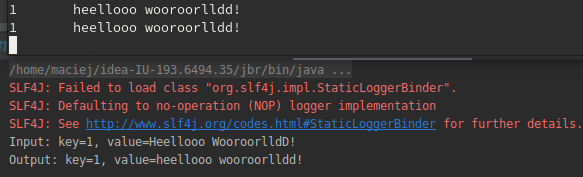
Po wpisaniu do producenta w konsoli wiadomości powinniśmy dostać podobny rezultat.
De/Serializacja z łapy
Najczęściej używanym formatem jest JSON, więc utworzyłem prostą klasę, która przedstawia osobę.
public class Person {
public String name;
public int age;
}
Spróbujmy przekształcić imię tak, by zaczynało się wielką literą. Dodamy również filtr, który będzie zatrzymywał osoby poniżej 18 roku życia.
builder.<String, String>stream(INPUT_TOPIC)
.peek(
(key, value) -> System.out.println("Input: key=" + key + ", value=" + value)
)
.mapValues(v -> {
try {
return mapper.readValue(v, Person.class);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
})
.mapValues((v -> {
v.name = v.name.substring(0, 1).toUpperCase() + v.name.substring(1).toLowerCase();
return v;
}))
.filter((k, v) -> v.age >= 18)
.mapValues(v -> {
try {
return mapper.writeValueAsString((v));
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
})
.peek(
(key, value) -> System.out.println("Output: key=" + key + ", value=" + value)
)
.to(OUTPUT_TOPIC, Produced.with(Serdes.String(), Serdes.String()));
Jak widzisz w liniach 5-11, w związku z tym, że zakładamy na wejściu string, sami musimy sparsować obiekt

Poison Pill
Jak widać wyżej, jakoś to działa. Co natomiast w przypadku gdy serializacja się nie uda?

Kafka Stream rzuca błędem i przestaje działać. Możemy dodać obsługę niezłapanych wyjątków w strumieniu, ale aplikacja i tak przestanie działać. O takich wiadomościach psujących strumień mówi się posion pills. Weź pod uwagę, że dopóki taka wiadomość jest w kolejce, aplikacja będzie się psuć. Dlatego warto ustawić czasową retencję na topic-u gdy bawimy się Kafka Streams.
streams.setUncaughtExceptionHandler((Thread thread, Throwable throwable) -> {
System.err.println("oh no! error! " + throwable.getMessage());
});
De/Serializacja nie z łapy
Jest lepszy sposób na de/serializacje. Najpierw musimy napisać klasy implementujące interfejsy Serializer i Deserializer.
public class PersonSerializer implements Serializer {
private static final Charset CHARSET = Charset.forName("UTF-8");
static private Gson gson = new Gson();
@Override
public void configure(Map configs, boolean isKey) {
}
@Override
public byte[] serialize(String s, Object o) {
String object = gson.toJson(o);
// Return the bytes from the String 'line'
return object.getBytes(CHARSET);
}
@Override
public void close() {
}
}
public class PersonDeserializer implements Deserializer<Person> {
private static final Charset CHARSET = Charset.forName("UTF-8");
static private Gson gson = new Gson();
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
@Override
public Person deserialize(String s, byte[] bytes) {
String person = new String(bytes, CHARSET);
return gson.fromJson(person, Person.class);
}
@Override
public void close() {
}
}
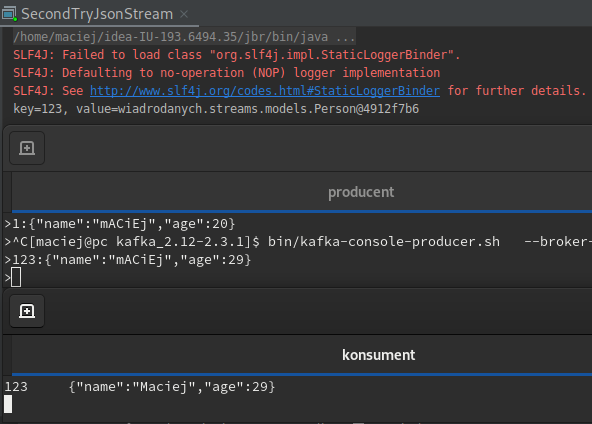
Teraz zamiast podawania w konfiguracji domyślnych SERDE, dostarczymy je tworząc strumień. Kod strumienia wygląda teraz tak:
builder.stream(INPUT_TOPIC, Consumed.with(Serdes.String(), personSerde))
.peek(
(key, value) -> System.out.println("key=" + key + ", value=" + value)
)
.mapValues((v -> {
v.name = v.name.substring(0, 1).toUpperCase() + v.name.substring(1).toLowerCase();
return v;
}))
.filter((k, v) -> v.age >= 18)
.to(OUTPUT_TOPIC, Produced.with(Serdes.String(), personSerde));
Peek dużo nam nie mówi, bo teraz dostajemy obiekt. Aplikacja działa tak jak wcześniejsza, ale kod jest czytelniejszy.
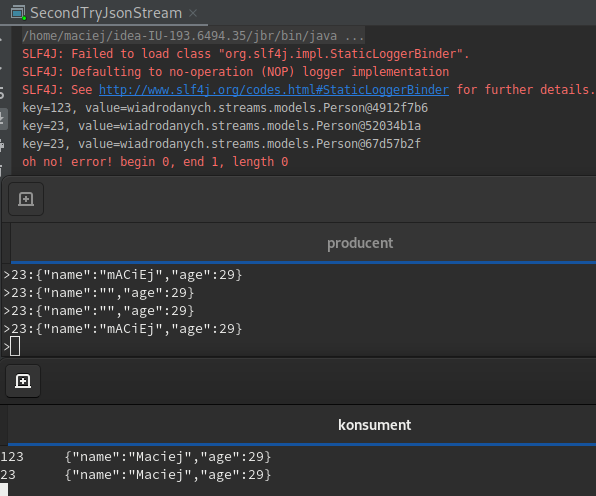
Poison Pill
Co się stanie jak wrzucimy do topic-a poprzedni poison pill? Jeśli się przygotujemy to nic. Jak dodamy do konfiguracji strumienia klasę LogAndContinueExceptionHandler lub swoją implementującą DeserializationExceptionHandler, możemy obsłużyć wyjątek dezerializacji i kontynuować pracę programu.
private static Properties createProperties() {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wiaderko-json-stream");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29092");
props.put(StreamsConfig.DEFAULT_DESERIALIZATION_EXCEPTION_HANDLER_CLASS_CONFIG, LogAndContinueExceptionHandler.class);
return props;
}

Niestety w ten sposób ratujemy się tylko w przypadku błędów z parsowaniem. Gdy podamy pusty string metoda mapValues rzuci wyjątkiem i wszystko się rozsypie.
Co dalej?
Jak widzisz, problem ze strumieniem nadal pozostał. Oto tematy Kafka Streams, które chcę poruszyć w przyszłości:
- Jak obsługiwać błędy?
- Co zrobić z błędnymi wiadomościami?
- Jak to się testuje?
- Agregacje. O co chodzi z tym KTable itp.
Jeśli masz jakieś pomysły/uwagi, proszę, napisz w komentarzu.
Repozytorium
https://github.com/zorteran/wiadro-danych-kafka-streams/tree/kafka_streams_101

4 komentarze do “Kafka Streams 101”