

Apache Spark to jedna z najpopularniejszych platform do rozproszonego przetwarzania i analizy danych. Choć kojarzona jest farmą serwerów, Hadoop’em i technologiami chmurowymi, z powodzeniem możesz odpalić ją na swojej maszynie. W tym wpisie dowiesz się kilku sposobów na konfiguracje deweloperskiego środowiska Apache Spark.
Założenia
Bazowym systemem w tym przypadku jest Ubuntu Desktop 20.04 LTS.
spark-shell
Pierwszym sposobem jest uruchomienie Spark’a w terminalu. Zacznijmy od ściągnięcia Apache Spark. Możesz go pobrać tutaj. Po ściągnięciu musimy wypakować paczkę tar’em.
wget ftp://ftp.task.gda.pl/pub/www/apache/dist/spark/spark-3.0.0/spark-3.0.0-bin-hadoop3.2.tgz
tar zxvf spark-3.0.0-bin-hadoop3.2.tgz
Apache Spark napisany jest w Scali, co oznacza, że potrzebujemy wirtualnej maszyny Javy (JVM). W przypadku Spark 3.0 będzie to 11’ka
sudo apt install default-jre
Teraz wystarczy wejśc do katalogu bin i uruchomić spark-shell’a
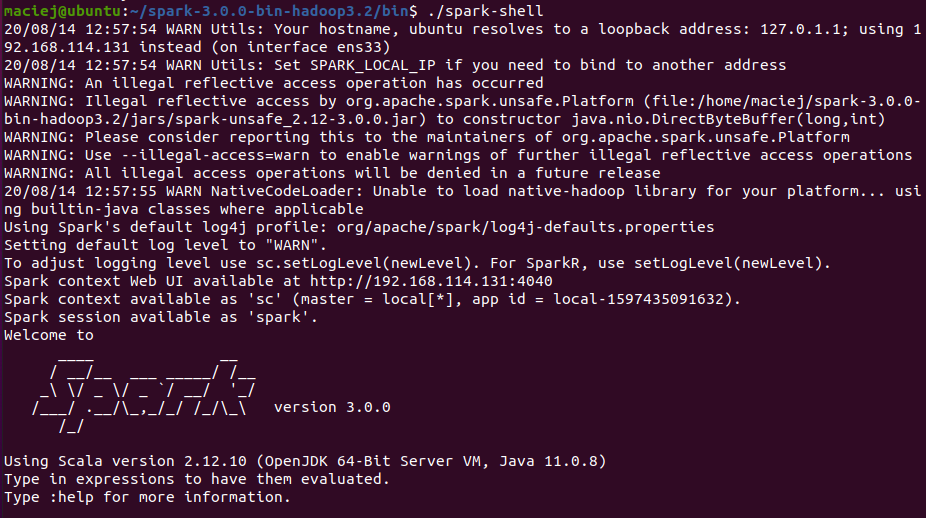
Jeśli potrzebujesz jakiejś biblioteki (np. chcesz pobrać dane z MySQL, coś z nimi zrobić i zapisać w innym miejscu), możesz dołączyć pliki jar ręcznie (–jars) lub pobierając je z repozytorium maven (–packages).
./spark-shell --driver-memory 8G --packages mysql:mysql-connector-java:5.1.49
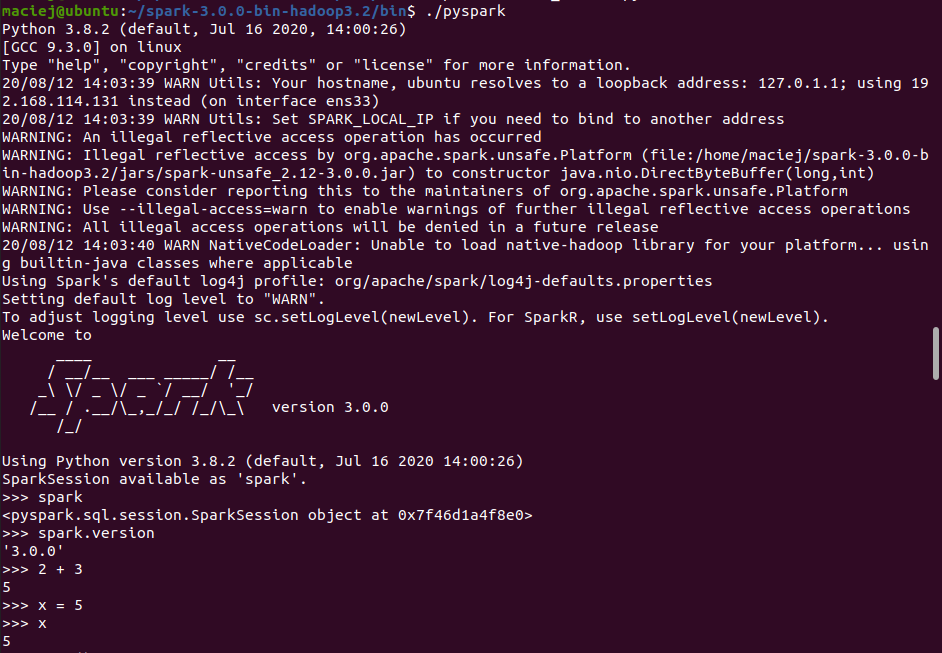
pyspark
W spark-shell piszemy w Scali, jeśli preferujesz Pythona, Twoim wyborem będzie PySpark.
W systemie nie ma pythona, więc zrobimy pewien myk. Zainstalujemy przy pomocy managera pakietów pip3, a przy okazji zainstaluje nam się python 🙂
sudo apt install python3-pip
Okazuje się jednak, że to nie wystarczy. Pyspark nie znajduje zmiennej python.
maciej@ubuntu:~/spark-3.0.0-bin-hadoop3.2/bin$ ./pyspark
env: ‘python’: No such file or directory
Musimy wskazać wersję Pythona za pomocą zmiennej środowiskowej.
export PYSPARK_PYTHON=python3
Teraz pyspark uruchamia się w terminalu.
pyspark w Jupyter Notebook
Większość osób korzystających z Pythona, bardziej niż terminal, preferuje notebooki. Najpopularniejszym jest Jupyter Notebook. Zainstalujmy go. Wykorzystamy do tego pip3, a potem dodamy folder /.local/bin do ścieżki.
pip3 install notebook
export PATH=$PATH:~/.local/bin
Po dodaniu poniższych zmiennych środowiskowych:
export PYSPARK_DRIVER_PYTHON="jupyter"
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
Jupyter Notebook odpali nam się automatycznie razem z pyspark’iem.
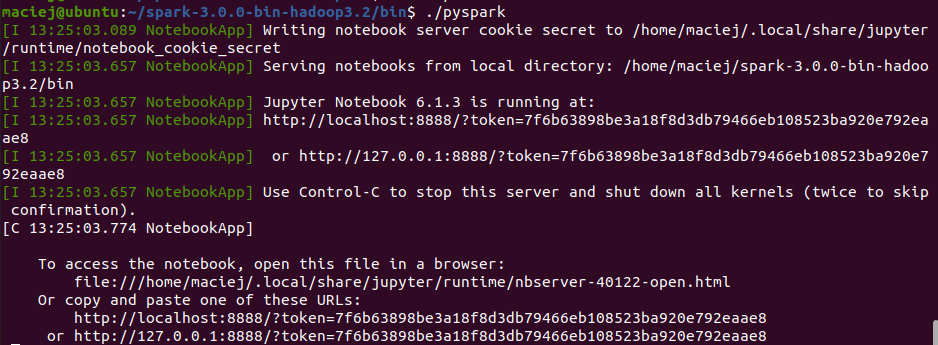
Jeśli potrzebujesz dołączyć do środowiska bibliotekę, skorzystaj z poniższej zmiennej środowiskowej.
export PYSPARK_SUBMIT_ARGS='--packages mysql:mysql-connector-java:5.1.49'
spylon (scala) w Jupter Notebook
Jeśli jednak wolisz używać języka Scala, jest opcja z kernelem spylon. Instalacja wygląda następująco:
pip3 install spylon-kernel
python3 -m spylon_kernel install --user
Musimy też ustawić zmienną środowiskową SPARK_HOME.
export SPARK_HOME=/home/maciej/spark-3.0.0-bin-hadoop3.2
Teraz po uruchomieniu jupyter notebook mamy dostęp do kernela spylon-kernel.
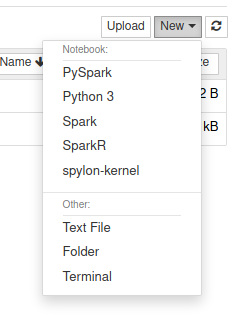

Jeśli potrzebujesz konkretnych paczek lub zmienić konfigurację, użyj %%init_spark
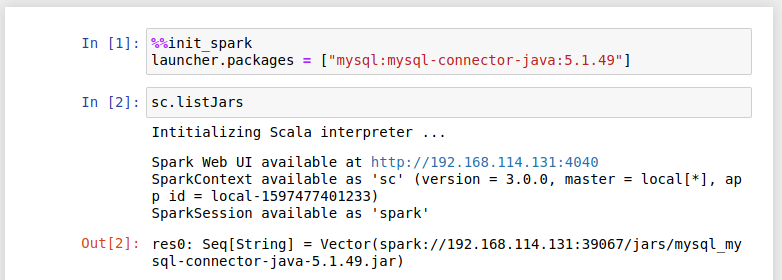
Projekt w IntelliJ IDEA
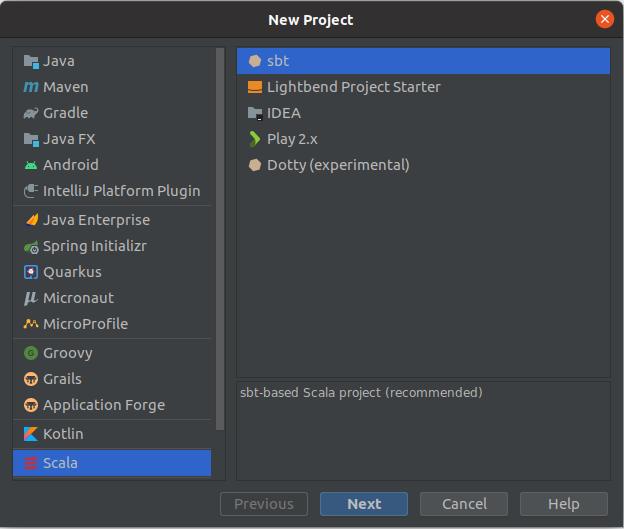
Przyda się plugin Scala.

Tworzymy nowy projekt Scala -> sbt.
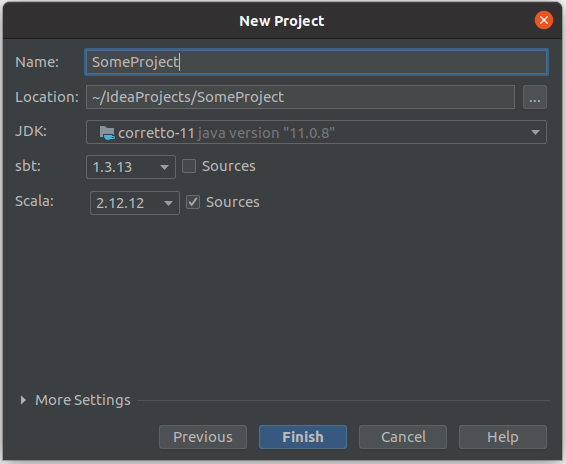
Wybieramy Scala 2.12 oraz JDK. Ja wybrałem Amazon Corretto 11.
Do pliku build.sbt dopiszmy potrzebne paczki.
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "3.0.0",
"org.apache.spark" %% "spark-sql" % "3.0.0"
)
Po załadowaniu zmian przez sbt możemy zacząć pisanie aplikacji w sparku. Utwórz obiekt w ścieżce src/main/scala o wybranej nazwie i możesz kodzić ?.
import org.apache.spark.sql._
object MyAwesomeApp {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.appName("MyAwesomeApp")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val df = Seq(
("x", 4),
("y", 2),
("z", 5)
).toDF("some_id", "some_int")
df.show()
}
}
Co dalej?
Jest jeszcze paczka sparkmagic, o której zrobię osobny wpis.

Hej,
jak zwykle super kontent, dzieki 🙂
Jesli moglbym cokolwiek dodac to osobiscie podobal mi sie “sposob na dockera”, np. tutaj jest dzialajacy obraz: https://hub.docker.com/r/bitnami/spark/
Dzięki 🙂 faktycznie zapomnialem o Dockerze, a czesto używam https://hub.docker.com/r/jupyter/all-spark-notebook/ . Zerknę na ten od bitnami
Od siebie dodałbym jeszcze wzmiankę o Zeppelin – mniej popularnym od Jupytera, ale pod pewnymi względami znacznie bardziej elastycznym notebooku.
Apache Zeppelin to faktycznie ciekawy notebook. Zastanawiam się, czy nie zrobić o nim oddzielnego wpisu.
A ja zrobiłem to tak https://wchmurze.cloud/index.php/2019/11/02/colab-zaiskrzyl-podczas-instalacji-apache-sparka/
Tym razem w Colabie
Super wpis. Wstyd przyznać, ale nigdy wcześniej nie słyszałem o google colab ?. Będę musiał zbadać temat.