

W poprzedniej części, po przygotowaniu danych w Apache Spark-u i zapisaniu ich w formacie Parquet, widać było sporą poprawę w czasie wykonania zapytań. Czy było to konieczne? Jakie są inne formaty danych i który wypada korzystniej? Przekonajmy się.
Jest to jeden z artykułów dotyczących tego zbioru danych:
- Oczyszczenie i wykonanie prostych agregacji
- Porównanie formatów ORC, Parquet, JSON, CSV (tutaj jesteś)
- Osobiste haveibeenpwned – partycjonowanie danych
Jakie formaty porównamy?
- CSV – plik tekstowy z wartościami rozdzielonymi przecinkami
- JSON – czyli klasyk jeśli chodzi o WebAPI/REST
- Apache Parquet oraz Apache ORC – formaty zorientowane kolumnowo. W porównaniu do np. CSV, wartości w obrębie kolumny znajdują się obok siebie. Pobierając jedną kolumnę przetwarzana jest tylko część pliku. Nie ma potrzeby przejścia przez wszystkie wiersze.
Zapis do pliku
Najpierw zapisałem wszystko do jednego pliku (dla każego formatu). Z lenistwa zamiast pisać kod w scali, budować jar-a i wrzucać go na serwer, napisałem kod w pythonie (pyspark) .
from pyspark.sql import *
spark = SparkSession.builder.appName('breach_to_multiple_files').getOrCreate()
breach = spark.read.parquet("/data/breach_parquet/breach.parquet")
breach.coalesce(1).write.option("compression","gzip").parquet("/data/breach_parquet_gzip")
breach.coalesce(1).write.option("compression","none").parquet("/data/breach_parquet_none")
breach.coalesce(1).write.option("compression","none").orc("/data/breach_orc_none")
breach.coalesce(1).write.option("compression","zlib").orc("/data/breach_orc_zlib")
breach.coalesce(1).write.option("compression","snappy").orc("/data/breach_orc_snappy")
breach.coalesce(1).write.csv("/data/breach_csv")
breach.coalesce(1).write.json("/data/breach_json")
Użyłem coalesce(1). Czas operacji był dłuższy, ale zależało mi na jednym pliku wyjściowym. Wybrałem też różne rodzaje kompresji dla Parquet i ORC.
Wyniki
Porównałem rozmiar pliku jaki powstał, szybkość wykona się count() oraz szybkość wykonania się Top 10 haseł z poprzedniego artykułu. Użyłem Apache Zeppelin z domyślną konfiguracją interpretera. Wiem, że wyniki można było by podkręcić odpowiednią konfiguracją przydzielonych rdzeni/pamięci i ilością executorów. Chodzi bardziej o pokazanie czy jest widoczna różnica między formatami.
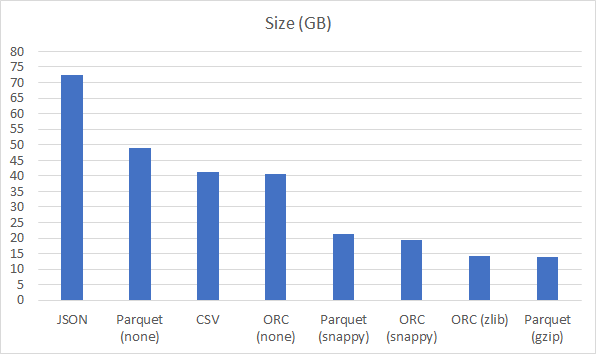
Rozmiar
Największym przegranym jest JSON. Powtarzające się metadane znacznie powiększyły plik. Co ciekawe “fizyki nie oszukasz”. Parquet i ORC bez kompresji są na podobnym poziomie co CSV. Natomiast kompresja snappy i zlib/gzip dla Parquet i ORC zapewnia rozmiar na podobnym poziomie.
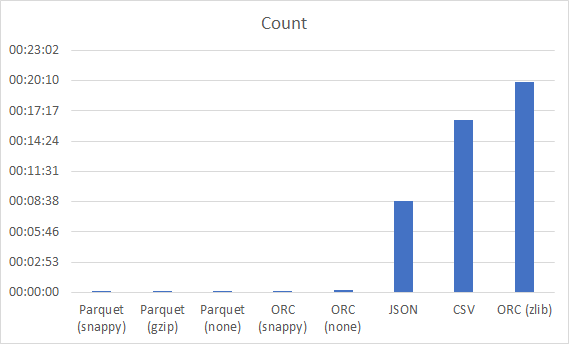
Count()
Tutaj niespodzianka. Parquet i ORC zawierają w sobie metadane (w tym ilość rekordów), ale dla kompresji zlib jednak jakby te informacje nie istniały. JSON pomimo wielkości wypada lepiej niż CSV, ale samo wczytanie JSON-a do DataFrame trwało 33 minuty!
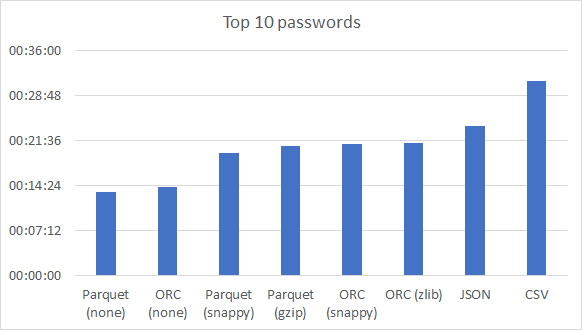
Top 10 haseł
Najszybciej wykonały się zapytania na nieskompresowanych Parquet i ORC. Kompresja snappy/gzip/zlib na podobnym poziomie. Ciekawy jest Parquet w kombinacji z gzip-em. Zajmuje zauważalnie mniej miejsca niż snappy, a dużo mu nie odbiega w czasie zapytania. JSON ponownie wygrywa z CSV, ale pytanie czy nie powinniśmy doliczyć 33 minut ładowania pliku do DataFrame-a.
Wnioski
Na pewno lepiej unikać JSON/CSV. Czy używać ORC czy Parquet? Ja zostanę przy Parquet. Argumentem za jest to, że używa go Delta Lake.

2 komentarze do “Półtora miliarda haseł w Spark – część 2 – formaty danych”