

Deduplikacja to W systemach rozproszonych występują tylko dwa trudne problemy:
2. Dostarczenie wiadomości dokładnie raz
1. Gwarantowana kolejność wiadomości
2. Dostarczenie wiadomości dokładnie raz.
Inny mi słowy: w tym wpisie zajmiemy się deduplikacją zdarzeń 😁. Ostatnio miałem z tym problem w SIEM’ie, więc padło na Logstash’a.
Dlaczego jest to istotne?
Jak pewnie wiesz, świat nie jest idealny. Tym bardziej świat systemów rozproszonych. Ludzie popełniają błędy. Aplikacje przestają działać. Sieć jest niewydolna, a pakiety czasami nie docierają do adresata.
Jeśli spotkałeś lub spotkałaś się z systemami kolejkowymi takimi jak Apache Kafka, Rabbit MQ, Apache Pulas, AWS SQS, Azure Event Hub i podobne, na pewno znajome Ci są poniższe koncepcje:
- No quarantee – Brak gwarancji dostarczenia wiadomości. Konsument może otrzymać ją raz, wiele razy, albo wcale
- At most once – Konsument otrzyma wiadomość najwyżej raz
- At least once – Konsument otrzyma wiadomość co najmniej raz, czyli mogą wystąpić duplikaty
- Exactly once – Konsument otrzyma wiadomość tylko raz
Czy zawsze potrzebujemy gwarancji otrzymania wiadomości tylko raz? Nie. Szczególnie, że ma to swoją cenę. W końcu najszybszą metodą wysyłania wiadomości jest fire and forget, bez oczekiwania na potwierdzenie odbioru. Tak czy inaczej, gdy zapomnimy o tym fakcie podczas projektowania systemu, możemy się potem nieźle zdziwić.
Dlaczego Logstash?
Logstash wykorzystywany jest głównie w parze z Elasticsearch i Kibana w ramach Elastic Stack, choć można wykorzystywać go też samodzielnie. Źródła danych bywają różne. To samo dotyczy sieci. Możemy zabezpieczyć się przed odebraniem duplikatów logów/wiadomości/rekordów, aby nie zaśmiecać widoku analitykom.
Kolejny przypadek użycia (który wkrótce pewnie okaże się na blogu) to wysyłanie alertów. Alerty lubią się powtarzać. Szczególnie gdy alert zapięty jest na prostej regule. Prosty przykład: Gdy jakiś użytkownik nawiążę połączenie z adresem XYZ to wyślij powiadomienie na Slacku. Prosta czynność może spowodować lawinę połączeń, a co za tym idzie, lawinę powiadomień.
Dlaczego Redis?
Redis jest to baza NoSQL typu klucz-wartość przechowująca dane w pamięci operacyjnej. Czytaj: jest szybka. Prosta struktura odpowiada przypadkowi użycia jaki tutaj omawiam.
Podwójną zaletą Redis jest skalowalność. Dlaczego podwójną? Skalować możemy zarówno Redis’a, jak i Logstash’e. Redis będzie przechowywać odcinki palców/hashe tworzące unikalne wartości zdarzeń.
Kolejna zaleta to możliwość nadawania TTL, czyli czasu życia rekordu. Pozwoli to ograniczyć ilość miejsca potrzebnego przez dane w Redis’ie oraz utworzyć okno czasowe
Implementacja
Kod
Pipeline przez który przecodzą dane w Logstash’u dzieli się na 3 sekcje:
- Input – gdzie definiujemy źródła danych
- Filter – gdzie przekształcamy i filtrujemy dane
- Output – gdzie zapisujemy/wysyłamy dane
W tym przypadku pipeline przyjmuje dane z zapytań HTTP, deduplikuje za pomocą filtru ruby, a następnie wyświetla na konsoli.
input {
http {
port => 8888
}
}
filter {
ruby {
path => "/home/maciej/Desktop/logstash-7.14.0/config/pipelines/ruby_scripts/deduplicate.rb"
script_params => {
"fields" => ["field_1","field_2"]
"prefix" => "http_"
"ttl" => 10
}
}
mutate {
remove_field => ["host","headers","@version"]
}
}
output {
stdout {}
}
Filtr ruby
Logstash posiada ogrom filtrów, ale niestety nie posiada oficjalnego filtra obsługującego bazę Redis. Jest filtr do memcached, ale celowo go tutaj nie wykorzystuję.
Filtr ruby pozwala nam wykonać praktycznie każdą operację za pomocą skryptów napisanych w Ruby. Do pobierania i zapisywania pól rekordów wykorzystuje się Event API. Blok kodu można umieścić bezpośrednio w filtrze (pola codeoraz init) lub w oddzielnym pliku (jak powyżej).
Kod jest dość prosty i lekko sparametryzowany. Sprytne wykorzystanie script_params pozwala na ponowne wykorzystanie skryptu w przyszłych pipeline’ach.
def register(params)
require "redis";
$rc = Redis.new(:write_timeout => 5, :read_timeout => 5, :reconnect_attempts => 999999, url: "redis://localhost:6379/0")
@prefix = params["prefix"];
@fields = params["fields"];
@ttl = params["ttl"]
end
def filter(event)
begin
fields_values = @fields.map { |n| event.get(n).to_s }
combined = @prefix.to_s + fields_values.join("_")
if $rc.exists?(combined)
return []
end
$rc.set(combined, nil, ex: @ttl)
return [event];
rescue
return [event];
end
end
Metoda register służy do przygotowania parametrów skryptu i wszystkich potrzebnych bibliotek. W tym miejscu konfigurowany jest klient do bazy Redis.
Metoda filter wykonywana jest dla każdego rekordu przechodzącego przez filtr. W tym przypadku, na podstawie pól zdefiniowanych w parametrze fields, tworzony jest ciąg znaków który służy za klucz w bazie Redis. Jeśli takiego wpisu w bazie nie ma, to zostanie wpisany. Jeśli jest, rekord jest pomijany. Nie zapominajmy o KISS. Na wydajność kiedyś przyjdzie czas… 😅
Działanie
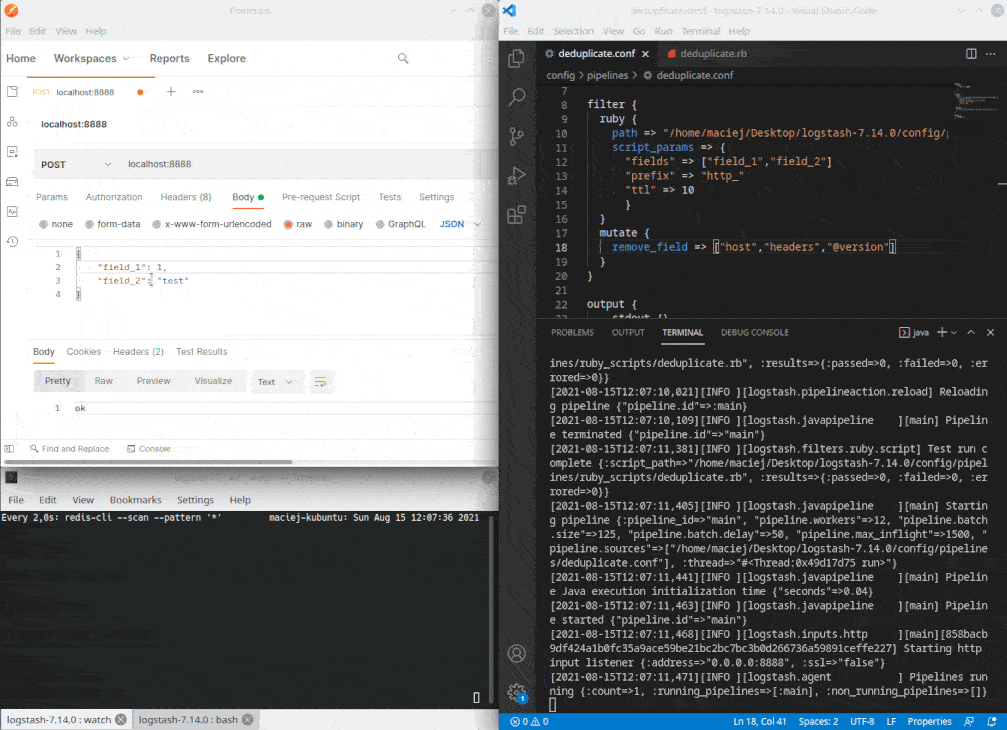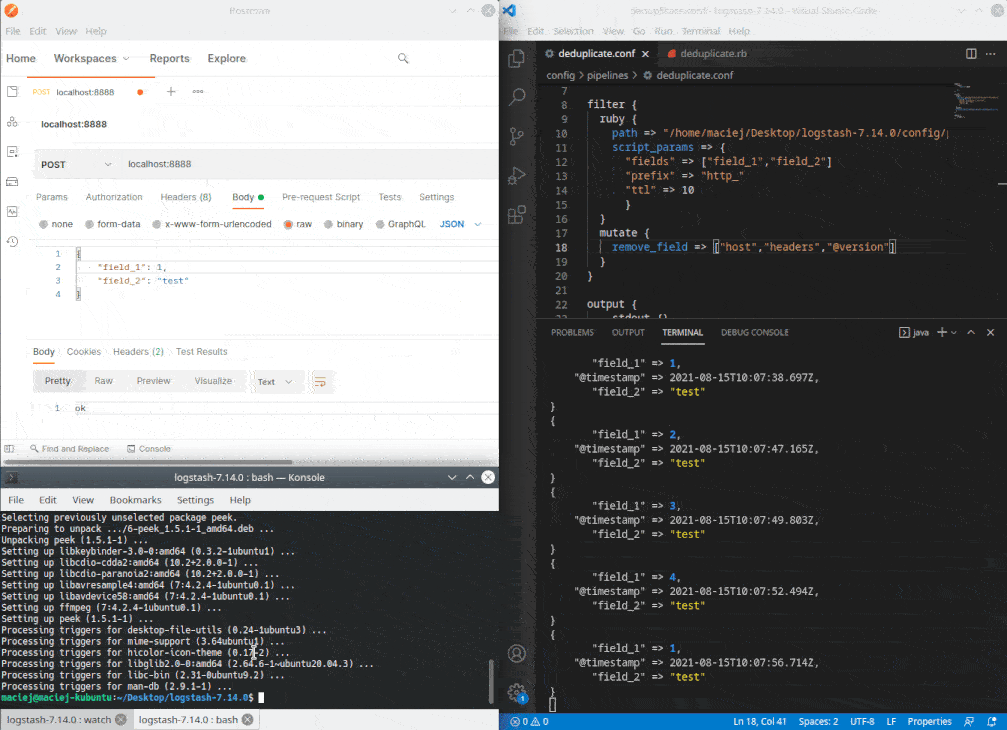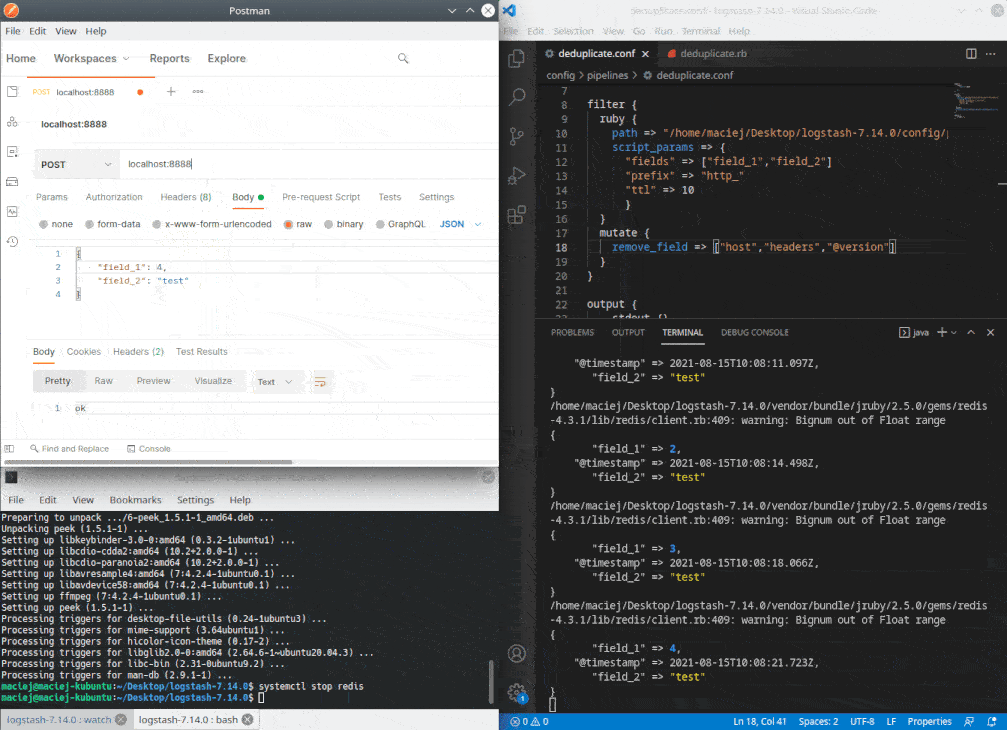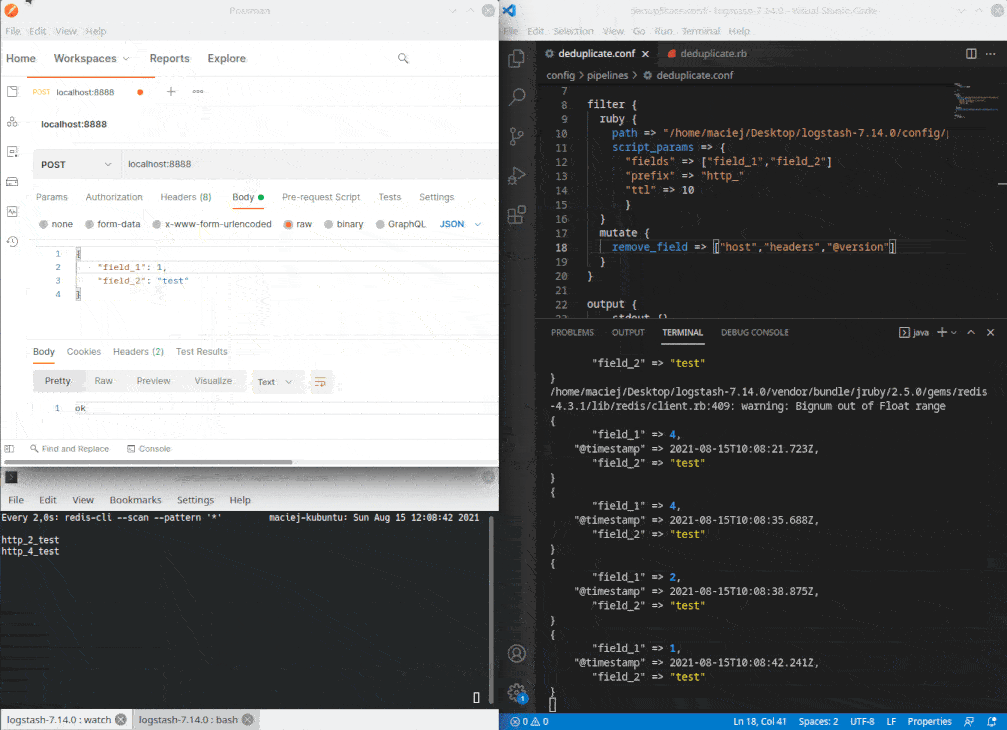
Repozytorium
https://github.com/zorteran/logstash-deduplication
