

Jednym z podstawowych narzędzi Data Scientist jest Pandas. Niestety nadmiar danych może znacznie utrudnić nam zabawę. Dlatego powstało Koalas. Biblioteka umożliwiająca korzystanie z Apache Spark w taki sposób, jakbyśmy robili to za pomocą Pandas.
Psst! Repozytorium z plikiem Jupyter znajdziesz na końcu wpisu.
Cel
Nie będziemy tutaj dokonywać niesamowitych, przełomowych odkryć. Na danych Movielens sprawdzimy, czy Koalas podoła prostym operacjom. Koalas w wersji 1.0.1, ale wynik może Cię lekko zaskoczyć.
Środowisko
Standardowo wykorzystam tutaj Dockera, a dokładnie kontener jupyter/all-spark-notebook/. Oprócz portu 8888 (jupyter), mapuję też port 4040 (Spark Web UI)
version: '3'
services:
notebook:
image: jupyter/all-spark-notebook
ports:
- 8888:8888
- 4040:4040
volumes:
- ./work:/home/jovyan/work
Pip i Spark Session
import sys
!{sys.executable} -m pip install koalas
import databricks.koalas as ks
import pandas as pd
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Przygotowanie Spark DataFrame
movies_df = (spark.read
.option("header", "true")
.option("inferSchema", "true")
.csv("./movies.csv")
)
ratings_df = (spark.read
.option("header", "true")
.option("inferSchema", "true")
.csv("./ratings.csv")
)
links_df = (spark.read
.option("header", "true")
.option("inferSchema", "true")
.csv("./links.csv")
)
tags_df = (spark.read
.option("header", "true")
.option("inferSchema", "true")
.csv("./tags.csv")
)
movies_df.registerTempTable("movies")
ratings_df.registerTempTable("ratings")
links_df.registerTempTable("link")
tags_df.registerTempTable("tags")
Przygotowanie Koalas DataFrame
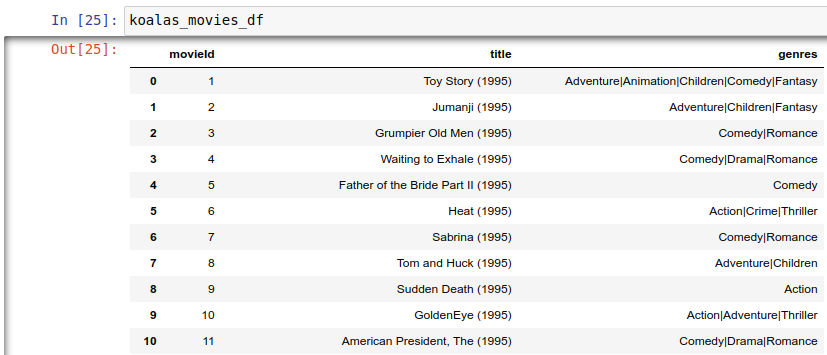
koalas_movies_df = ks.DataFrame(movies_df)
koalas_ratings_df = ks.DataFrame(ratings_df)
koalas_links_df = ks.DataFrame(links_df)
koalas_tags_df = ks.DataFrame(tags_df)
W Spark Web UI widać, że faktycznie pod skorupą Pandas, Koalas napędza Spark.
Top 10 najczęściej ocenianych filmów
Wszystkie rozwiązania są ok. Osobiście najbardziej pasuje mi deklaratywny styl SQL-a.
PySpark
from pyspark.sql.functions import col
movies_with_ratings = movies_df.join(ratings_df, movies_df.movieId == ratings_df.movieId)
(movies_with_ratings
.groupBy("title")
.count()
.orderBy(col("count").desc())
.show(10, False))
+-----------------------------------------+-----+
|title |count|
+-----------------------------------------+-----+
|Forrest Gump (1994) |329 |
|Shawshank Redemption, The (1994) |317 |
|Pulp Fiction (1994) |307 |
|Silence of the Lambs, The (1991) |279 |
|Matrix, The (1999) |278 |
|Star Wars: Episode IV - A New Hope (1977)|251 |
|Jurassic Park (1993) |238 |
|Braveheart (1995) |237 |
|Terminator 2: Judgment Day (1991) |224 |
|Schindler's List (1993) |220 |
+-----------------------------------------+-----+
only showing top 10 rows
Koalas/Pandas
koalas_movies_with_ratings = ks.merge(koalas_movies_df, koalas_ratings_df)
(koalas_movies_with_ratings
.groupby('title')
.size()
.sort_values(ascending=False)[:10])
title
Forrest Gump (1994) 329
Shawshank Redemption, The (1994) 317
Pulp Fiction (1994) 307
Silence of the Lambs, The (1991) 279
Matrix, The (1999) 278
Star Wars: Episode IV - A New Hope (1977) 251
Jurassic Park (1993) 238
Braveheart (1995) 237
Terminator 2: Judgment Day (1991) 224
Schindler's List (1993) 220
Name: count, dtype: int64
Spark SQL
spark.sql("""
SELECT title, COUNT(*) as CNT
FROM movies
LEFT JOIN ratings ON movies.movieId = ratings.movieID
GROUP BY title
ORDER BY CNT DESC
LIMIT 10
""").show(10,False)
+-----------------------------------------+---+
|title |CNT|
+-----------------------------------------+---+
|Forrest Gump (1994) |329|
|Shawshank Redemption, The (1994) |317|
|Pulp Fiction (1994) |307|
|Silence of the Lambs, The (1991) |279|
|Matrix, The (1999) |278|
|Star Wars: Episode IV - A New Hope (1977)|251|
|Jurassic Park (1993) |238|
|Braveheart (1995) |237|
|Terminator 2: Judgment Day (1991) |224|
|Schindler's List (1993) |220|
+-----------------------------------------+---+
Top 10 filmów wg średnich ocen (ale tylko takich, które mają >100 ocen)
PySpark
import pyspark.sql.functions as F
(movies_with_ratings
.groupBy("title")
.agg(
F.count(F.lit(1)).alias("cnt"),
F.avg(col("rating")).alias("avg_rating")
)
.filter("cnt > 100")
.orderBy(col("avg_rating").desc())
.select("title","avg_rating")
.show(10, False))
+-----------------------------------------+-----------------+
|title |avg_rating |
+-----------------------------------------+-----------------+
|Shawshank Redemption, The (1994) |4.429022082018927|
|Godfather, The (1972) |4.2890625 |
|Fight Club (1999) |4.272935779816514|
|Godfather: Part II, The (1974) |4.25968992248062 |
|Departed, The (2006) |4.252336448598131|
|Goodfellas (1990) |4.25 |
|Dark Knight, The (2008) |4.238255033557047|
|Usual Suspects, The (1995) |4.237745098039215|
|Princess Bride, The (1987) |4.232394366197183|
|Star Wars: Episode IV - A New Hope (1977)|4.231075697211155|
+-----------------------------------------+-----------------+
only showing top 10 rows
Koalas/Pandas
Jak widać poniżej, nie wszystko jest zaimplementowane. Trzeba kombinować ?.
# PandasNotImplementedError: The method `pd.DataFrame.insert()` is not implemented yet.
# :-(
koalas_top_100 = (koalas_movies_with_ratings
.insert(0, 'cnt', 1)
.groupby('title')
.agg(
{
'rating': 'avg',
'cnt': 'size'
}
))
Koalas miał problem z wykorzystaniem DataFrame jako parametr operacji na innym DataFrame. Co ciekawe miałem też tak w innym przypadku, gdzie używałem tego samego DataFrame. Tak czy inaczej, musiałem włączyć opcję compute.ops_on_diff_frames.
koalas_top_10 = (koalas_movies_with_ratings
.assign(cnt=1)
.groupby('title')
.agg({
'rating': 'avg',
'cnt': 'count'
})
)
over_100_cnt = koalas_top_10['cnt'] > 100
ks.set_option('compute.ops_on_diff_frames', True)
koalas_top_10 = (koalas_top_10[over_100_cnt]
.where(koalas_top_10.cnt>100)
.sort_values(by='rating', ascending=False)
)

Spark SQL
Tutaj wygląda to dziecinnie prosto. Jak dla mnie, SQL znów wygrywa.
spark.sql("""
SELECT title, AVG(rating) as avg_rating
FROM movies
LEFT JOIN ratings ON movies.movieId = ratings.movieID
GROUP BY title
HAVING COUNT(*) > 100
ORDER BY avg_rating DESC
LIMIT 10
""").show(10,False)
+-----------------------------------------+-----------------+
|title |avg_rating |
+-----------------------------------------+-----------------+
|Shawshank Redemption, The (1994) |4.429022082018927|
|Godfather, The (1972) |4.2890625 |
|Fight Club (1999) |4.272935779816514|
|Godfather: Part II, The (1974) |4.25968992248062 |
|Departed, The (2006) |4.252336448598131|
|Goodfellas (1990) |4.25 |
|Dark Knight, The (2008) |4.238255033557047|
|Usual Suspects, The (1995) |4.237745098039215|
|Princess Bride, The (1987) |4.232394366197183|
|Star Wars: Episode IV - A New Hope (1977)|4.231075697211155|
+-----------------------------------------+-----------------+
Top 10 lat wg średnich ocen
Nie ma kolumny rok. Trzeba wyciągnąć tę informację z tytułu.
PySpark
(movies_with_ratings
.withColumn('year', F.regexp_extract(F.col('title'),'.*\((.*)\).*', 1))
.groupBy("year")
.agg(
F.avg(col("rating")).alias("avg_rating")
)
.orderBy(col("avg_rating").desc())
.show(10, False))
+---------+-----------------+
|year |avg_rating |
+---------+-----------------+
|2006–2007|5.0 |
|1917 |4.5 |
|1930 |4.205882352941177|
|1921 |4.1 |
|1934 |4.088235294117647|
|1944 |4.043478260869565|
|1957 |4.03953488372093 |
|1954 |4.009191176470588|
|1926 |4.0 |
|1908 |4.0 |
+---------+-----------------+
only showing top 10 rows
Zaraz zaraz, co to ma być?
Pewnie zastanawiasz się, czy operacja withColumn po join jest dobrym pomysłem. Otóż ostatecznie kolejność może być różna. Wywołania w Apache Spark są leniwe (Lazy Evaluation). Zanim ruszy maszyna, wywoływana jest seria optymalizacji (na poziomie zarówno logicznym, jak i fizycznym) która przyśpiesza realizację kodu. Co więcej, w najnowszym Apache Spark 3.0 dodano Dynamic Partition Prunning i Adaptive Query Execution, co czyni Sparka jeszce szybszym. Sprawdźmy, co będzie w tym przypadku.
Wykonanie metody explain na dataframe pokazuje, że join jest wykonywany przed regexp, czyli mój kod jest słaby ?. Regexp przed joinem da to samo, a będzie operował na mniejszym zbiorze danych.
== Physical Plan ==
*(4) Sort [avg_rating#942 DESC NULLS LAST], true, 0
+- Exchange rangepartitioning(avg_rating#942 DESC NULLS LAST, 200)
+- *(3) HashAggregate(keys=[year#924], functions=[avg(rating#472)])
+- Exchange hashpartitioning(year#924, 200)
+- *(2) HashAggregate(keys=[year#924], functions=[partial_avg(rating#472)])
+- *(2) Project [rating#472, regexp_extract(title#455, .*\((.*)\).*, 1) AS year#924]
+- *(2) BroadcastHashJoin [movieId#454], [movieId#471], Inner, BuildLeft
:- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)))
: +- *(1) Project [movieId#454, title#455]
: +- *(1) Filter isnotnull(movieId#454)
: +- *(1) FileScan csv [movieId#454,title#455] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/home/jovyan/work/movies.csv], PartitionFilters: [], PushedFilters: [IsNotNull(movieId)], ReadSchema: struct<movieId:int,title:string>
+- *(2) Project [movieId#471, rating#472]
+- *(2) Filter isnotnull(movieId#471)
+- *(2) FileScan csv [movieId#471,rating#472] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/home/jovyan/work/ratings.csv], PartitionFilters: [], PushedFilters: [IsNotNull(movieId)], ReadSchema: struct<movieId:int,rating:double>
Koalas/Pandas
Tutaj niestety znów pojawił się błąd NotImplementedError. Tym razem nie ma metody extract. W tym miejscu postanowiłem przerwać “eksperyment”. Doświadczony “pandziaż” pewnie obszedłby ten problem na 10 innych sposobów. Koalas jest to naprawdę obiecujący projekt, ale jak widać, mogą być z nim problemy.
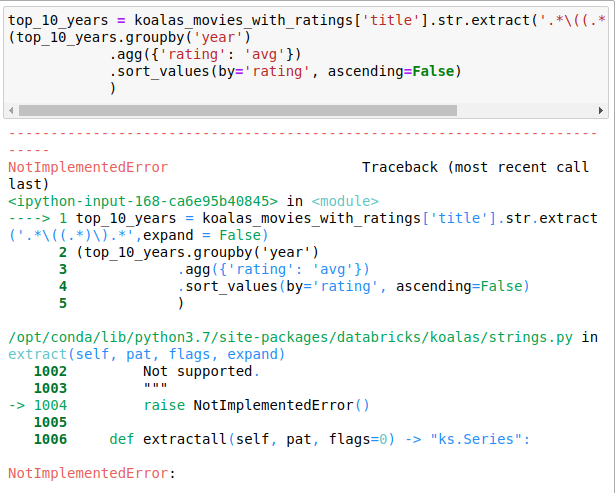
Matplotlib
To może z innej beczki. Czy wykresiki działają? Ależ owszem.

Konwersja Koalas => Pandas
Konwersja opiera się na wykonaniu metody toPandas()

Nie wszystkie operacje musimy wykonywać na klastrze. Możemy wykroić kawałek tortu i pójśc z nim do swojego domowego warsztatu.
Repozytorium
https://github.com/zorteran/wiadro-danych-koalas-pandas-fun
Podsumowanie
Uważam, że warto obserwować ten projekt. Stoi za nim databricks. Wiedzą, że grono Data Scientists mają swoje przyzwyczajenia i tak łatwo nie przejdą na PySparka.

> toPandas()
kthxbye
?♂️