
W poprzednim wpisie udokumentowałem utworzenie przepływu danych wykorzystującego technologie takie jak Kafka, Kafka Streams, Logstash i Elasticsearch. Po kilku dniach pracy mam już wystarczającą ilość danych, aby przekonać się jakie możliwości analizy danych transportu miejskiego umożliwia Elasticsearch i Kibana.
Czytaj dalej „Analiza Danych Transportu Miejskiego Warszawy w Kibana i Elasticsearch”Tag: ztm
Kafka Streams 202 – Dockeryzacja aplikacji, czyli Kafka w kontenerze

Obrazy Dockera są łatwe w obsłudze. Nie musimy instalować konkretnej wersji środowiska, bibliotek i innych zależności. Wszystko powinno być zamknięte w abstrakcji zwanej kontenerem. Możemy je uruchamiać i skalować w Docker Swarm lub Kubernetes. W tym wpisie zajmiemy się dockeryzacją aplikacji Kafka Streams na przykładzie strumienia dla lokalizacji autobusów ZTM przedstawionym w poprzednim wpisie.
Czytaj dalej „Kafka Streams 202 – Dockeryzacja aplikacji, czyli Kafka w kontenerze”Wizualizacja map w Elasticsearch i Kibana – GPS komunikacji miejskiej

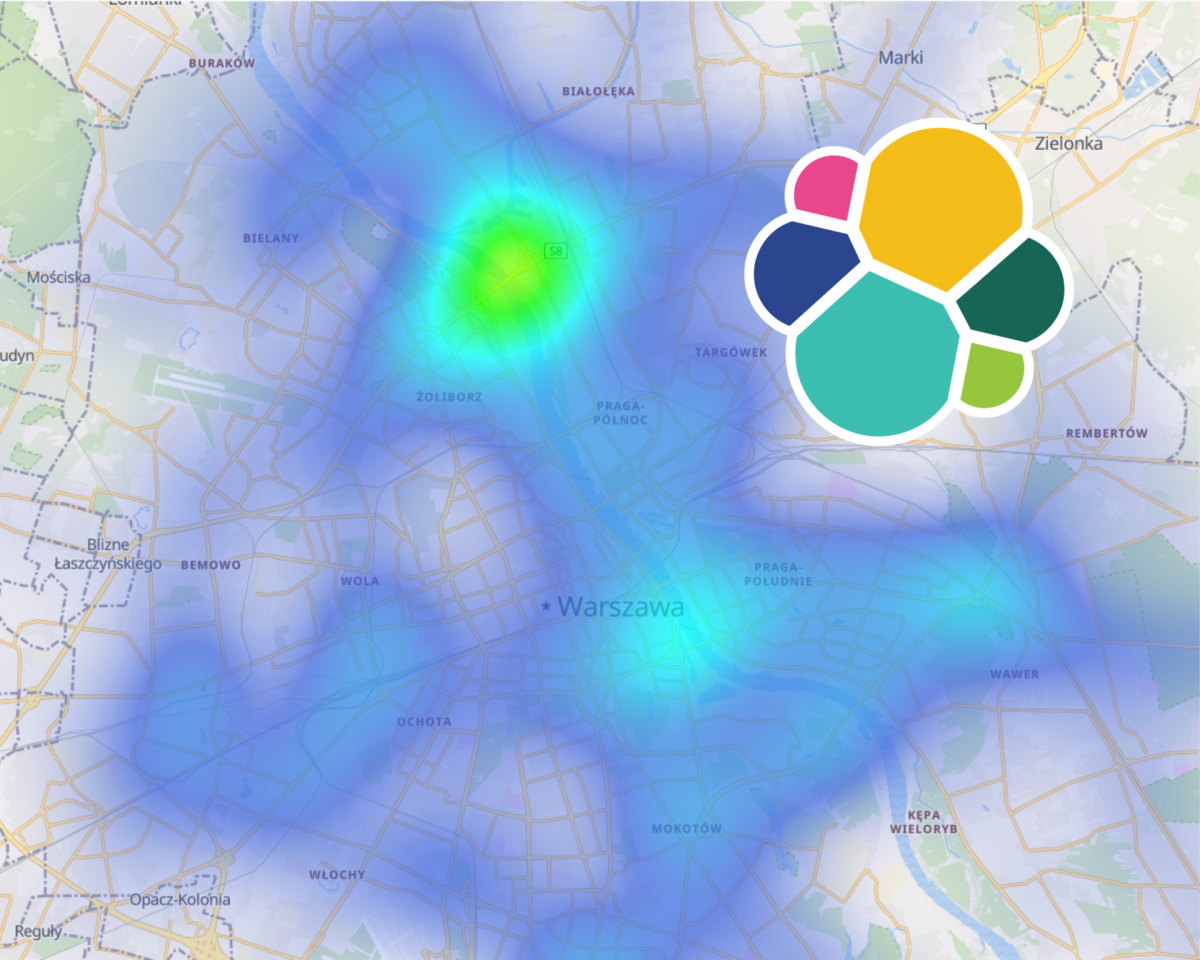
Myślisz o analizie i wizualizacji danych geo? Czemu nie spróbować Elasticsearch? Tzw. ELK (Elasticsearch + Logstash + Kibana) to nie tylko baza NoSQL. Jest to cały system, który umożliwia przechowywanie, wyszukiwanie, analizę i wizualizację danych z dowolnego źródła w czasie rzeczywistym. W tym przypadku wykorzystamy otwarte dane lokalizacji komunikacji miejskiej w Warszawie. Wspomniałem o nich w tym artykule.
Czytaj dalej „Wizualizacja map w Elasticsearch i Kibana – GPS komunikacji miejskiej”Obliczanie prędkości w Apache Spark – GPS komunikacji miejskiej

W poprzednim poście utworzyliśmy strumień danych lokalizacji pojazdów komunikacji miejskiej na jednym z topiców w Apache Kafka. Teraz dorwiemy się do tego strumienia z poziomu Apache Spark, zapiszemy trochę danych na HDFS i zobaczymy czy da się coś z nimi zrobić.
Czytaj dalej „Obliczanie prędkości w Apache Spark – GPS komunikacji miejskiej”