

W artykule dowiesz się dwóch oryginalnych sposobów na zmniejszenie danych w Elasticsearch nawet o 67%.
Czytaj dalej „Sprytny sposób na oszczędność miejsca w Elasticsearch”Kategoria: Elasticsearch
Threat Hunting LOLBAS w Elastic Stack na 2 sposoby (gościnnie Jupyter)

Indeksowania danych do klastra Elastic Stack to dobry moment na wyłuskanie wartości z danych. W przypadku Threat Hunting‘u, dobrze przygotowane dane mogą znacznie przyśpieszyć proces wyszukiwania zagrożeń i anomalii. W artykule uprościmy wyszukiwanie procesów LOLBAS.
Czytaj dalej „Threat Hunting LOLBAS w Elastic Stack na 2 sposoby (gościnnie Jupyter)”Jak wykryć phishing – feed CERT Polska w SIEM Elastic Stack.

Phishing to oszutwo, w którym przestępca podszywa się pod inną osobę lub instytucję w celu wyłudzenia poufnych informacji lub pieniędzy. Zespół CERT Polska chroni nas przed niebezpiecznymi stronami publikując listy. Dostępne są w wielu formatach. Jeśli znajdziesz złośliwą stronę, możesz zgłosić to do CSIRT NASK. W artykule wykorzystamy wymieniony feed w SIEM Elastic Stack i spróbujemy coś wykryć 😁.
Czytaj dalej „Jak wykryć phishing – feed CERT Polska w SIEM Elastic Stack.”Elasticsearch Runtime fields, albo analiza “polskiej szlachty” na podstawie danych z Facebook w Kibana

Elastic wprowadził mechanizm Runtime fields, a Facebook’owi przydarzył się wyciek. Jest to dobry pretekst, aby przetestować jedno i przyjrzeć się drugiemu 😁. Szczegóły o wycieku znajdziesz w artykule Niebezpiecznika.
Czytaj dalej „Elasticsearch Runtime fields, albo analiza “polskiej szlachty” na podstawie danych z Facebook w Kibana”Jak postawić klaster Elasticsearch? Fragment Kursu Elastic Stack

Najwięcej z Elasticsearch nauczyłem się eksperymentując na klastrze. Nie potrzebujemy do tego farmy serwerów. Wystarczy nasz komputer i instalacja lokalnego klastra.
Czytaj dalej „Jak postawić klaster Elasticsearch? Fragment Kursu Elastic Stack”Analiza danych z Twitter dla leni w Elastic Stack (Xbox VS PlayStation)

Dane z Twitter można pozyskać na wiele sposobów, ale komu chce się pisać kod 😉. Szczególnie taki, który będzie działał 24/7. W Elastic Stack można w prosty sposób zbierać i analizować dane z Twitter’a. Logstash ma gotowe wejście do zbierania strumienia tweet’ów. Kafka Connect omawiana w poprzednim artykule również ma taką opcję, jednak Logstash może wysyłać dane do wielu źródeł (w tym do Apache Kafka) i jest prostszy w obsłudze.
W artykule:
- Zapis strumienia tweetów do Elasticsearch w Logstash’u
- Wizualizacje w Kibana (Xbox vs PlayStation)
- Usunięcie tagów HTML dla keyword’a mechanizmem normalizacji
Elastic SIEM w pigułce (część 2)

Jest to kontynuacja poprzedniego wpisu. Tym razem przyjrzymy się zakładce Detections w Elastic SIEM. Naszym celem jest automatyzacja wykrywania IOC wykorzystując sprawdzone reguły. Przypomnijmy: Zainstalowaliśmy Elasticsearch + Kibana na jednej z maszyn. Monitorujemy maszynę z Ubuntu (Auditbeat, Filebeat, Packetbeat) i Windows 10 (Winlogbeat), choć w tym wpisie skupimy się na tej drugiej.
Czytaj dalej „Elastic SIEM w pigułce (część 2)”Elastic SIEM w pigułce (część 1)

Środowiska IT robią się coraz większe, rozproszone i ciężkie do zarządzania. Wszystkie komponenty systemu trzeba zabezpieczyć i monitorować przed cyber zagrożeniami. Potrzebna jest skalowalna platforma, która potrafi magazynować i analizować logi, metryki oraz zdarzenia. Rozwiązania SIEM potrafią kosztować niemałe pieniądze. W tym wpisie przyjrzymy się darmowemu rozwiązaniu dostępnego w Elastic Stack, czyli Elastic SIEM.
Czytaj dalej „Elastic SIEM w pigułce (część 1)”Dlaczego Elasticsearch kłamie? Jak działa Elasticsearch?

Elasticsearch zaskakuje nas swoimi możliwościami i szybkością działania, ale czy zwracane wyniki są prawidłowe? W tym wpisie dowiesz się jak Elasticsearch działa pod maską i dlaczego zwracane agregacje są pewnego rodzaju przybliżeniem.
Czytaj dalej „Dlaczego Elasticsearch kłamie? Jak działa Elasticsearch?”Analiza Danych Transportu Miejskiego Warszawy w Kibana i Elasticsearch
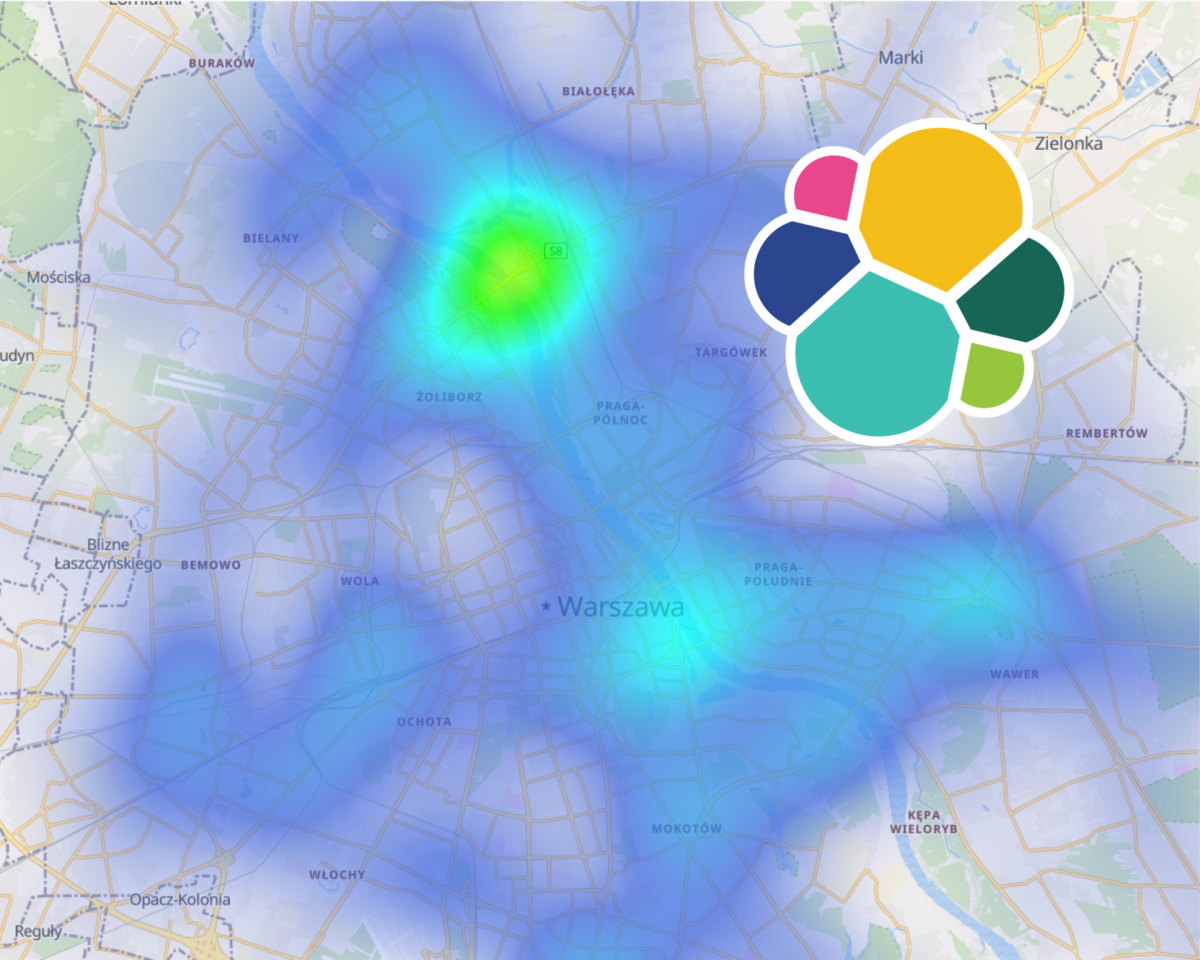
W poprzednim wpisie udokumentowałem utworzenie przepływu danych wykorzystującego technologie takie jak Kafka, Kafka Streams, Logstash i Elasticsearch. Po kilku dniach pracy mam już wystarczającą ilość danych, aby przekonać się jakie możliwości analizy danych transportu miejskiego umożliwia Elasticsearch i Kibana.
Czytaj dalej „Analiza Danych Transportu Miejskiego Warszawy w Kibana i Elasticsearch”