

Apache Spark potrafi pokonać wydajnością Pandas działając na pojedynczej maszynie, ale zaprojektowany został by działać w klastrze. Uruchomienie klastra może wydawać się trudne, ale w rzeczywistości to bułka z masłem. W tym wpisie dowiesz się jak uruchomić najprostszy z klastrów, czyli Standalone Spark Cluster.
Dlaczego Standalone Spark Cluster?
Ponieważ jest to proste i wydajne rozwiązanie. Masz je dostępne w binarkach Apache Spark. Głównym minusem jest ograniczenie w postaci kolejki FIFO dla zadań. Utrudnia to współdzielenie klastra przez wiele zadań/użytkowników, ale na początek jest wystarczające.
Binarki
Pierwszym krokiem jest ściągnięcie binarek Apache Spark. Ja wybrałem opcję dla Hadoop 3.2 wzwyż.
Po rozpakowaniu zobaczysz widok mniej więcej taki jak poniżej.
maciej@ubuntu:/opt/spark-3.0.1-bin-hadoop3.2$ ls -lah total 164K drwxr-xr-x 13 maciej maciej 4.0K Aug 28 02:22 . drwxr-xr-x 4 root root 4.0K Dec 7 11:04 .. drwxr-xr-x 2 maciej maciej 4.0K Aug 28 02:22 bin drwxr-xr-x 2 maciej maciej 4.0K Aug 28 02:22 conf drwxr-xr-x 5 maciej maciej 4.0K Aug 28 02:22 data drwxr-xr-x 4 maciej maciej 4.0K Aug 28 02:22 examples drwxr-xr-x 2 maciej maciej 20K Aug 28 02:22 jars drwxr-xr-x 4 maciej maciej 4.0K Aug 28 02:22 kubernetes -rw-r--r-- 1 maciej maciej 23K Aug 28 02:22 LICENSE drwxr-xr-x 2 maciej maciej 4.0K Aug 28 02:22 licenses -rw-r--r-- 1 maciej maciej 57K Aug 28 02:22 NOTICE drwxr-xr-x 7 maciej maciej 4.0K Aug 28 02:22 python drwxr-xr-x 3 maciej maciej 4.0K Aug 28 02:22 R -rw-r--r-- 1 maciej maciej 4.4K Aug 28 02:22 README.md -rw-r--r-- 1 maciej maciej 183 Aug 28 02:22 RELEASE drwxr-xr-x 2 maciej maciej 4.0K Aug 28 02:22 sbin drwxr-xr-x 2 maciej maciej 4.0K Aug 28 02:22 yarn
Master Node
Pierwszym krokiem jest postawienie Master Node. Interesują nas pliki ./sbin/start-master.sh i ./sbin/stop-master.sh. Teoretycznie wystarczy, że odpalimy ten pierwszy ale…

…jak widać można wystawić swojego sparka, jak to się mówi w branży, “dupą do świata”. Dlatego sprawdź czy wystawiasz master’a na dobrym hoście (parametr --host) i skonfiguruj firewalla. Ja idę na łatwiznę w ramach wpisu.
./sbin/start-master.sh --host 0.0.0.0
Domyślnie pod portem 8080 powinniśmy zobaczyć stronę Spark Master

Worker Node
W przypadku worker’ów interesować nas będą pliki ./sbin/start-slave.sh i ./sbin/stop-slave.sh. Wymagany parametr to adres master’a (domyślny port to 7077). Opcjonalnymi parametrami możemy m.in. ustalić hostname, ograniczyć liczbę rdzeni i RAM.
./sbin/start-slave.sh 192.168.114.131:7077

SparkPi demo
Czy klaster już działa? Sprawdźmy to. Możemy użyć ./bin/run-example aby uruchomić zadanie liczące PI. W parametrze --master podamy nasz namiar na klaster w postaci spark://url:port. Jak będziesz chciał podpiać Jupyter lub Apache Zeppelin, pamiętaj o spark://.
./run-example --master spark://localhost:7077 SparkPi 1000

Jak żyć z FIFO?
Załóżmy że wykonujesz obliczenia na klastrze, ale masz też Jupyter lub Apache Zeppelin, które chciałbyś podpiąć do klastra. Ograniczasz rdzenie --executor-cores, a RAM -- executor-memory, a tu nagle…
./run-example --master spark://localhost:7077 --executor-cores 1 SparkPi 1000
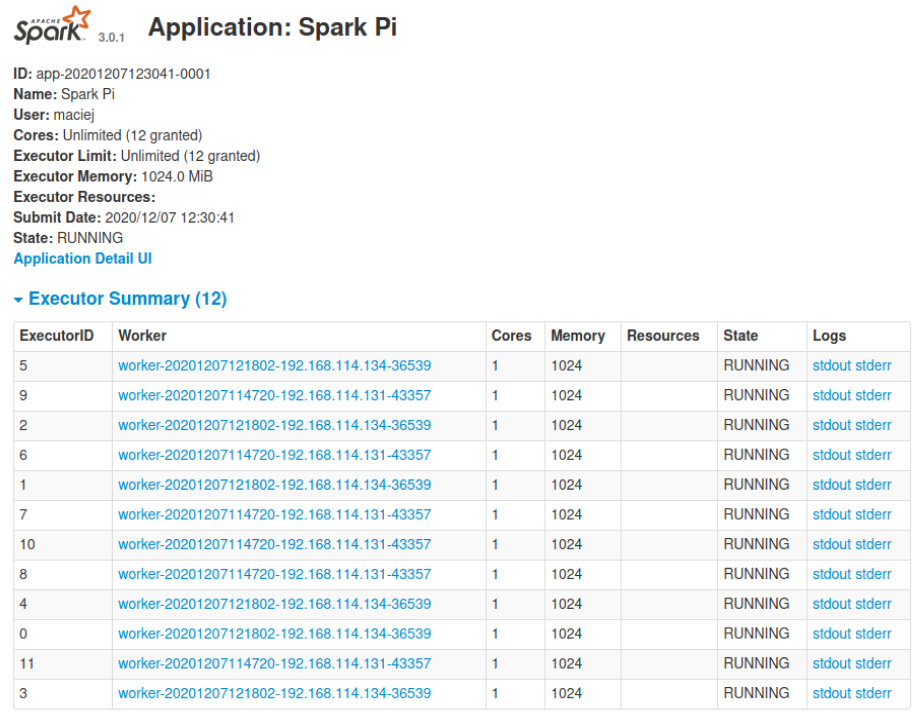
… wiele wykonawców z jednym rdzeniem. Możemy temu zaradzić ograniczając całkowitą liczbę rdzenia dla wykonawców za pomocą parametru --total-executor-cores. Nie jest to FAIR Scheduler w YARN, ale mamy jako taką możliwość podzielenia klastra.
spark-env.sh i spark-defaults.conf
W katalogu ./config/ znajdziesz pliki konfiguracyjne z których korzysta Apache Spark. W spark-defaults.conf możesz zawrzeć właściwości zadań, aby za każdym razem nie musieć ich podawać. W spark-env.sh natomiast masz o wiele większe możliwości konfiguracji sparka. Choćby SPARK_LOCAL_IP który przydać Ci się może, gdy masz wiele interfejsów sieciowych (a domyślnie spark wystawia się nie na tym co trzeba) i klaster nie widzi klienta.
Czy można szybciej?
Czy można szybko postawić i złożyć klaster? Pewnie. W ./conf/slaves możesz umieścić namiary na swoich worker’ów. Potem wstarczą skrypty ./sbin/start-all.sh i ./sbin/stop-all.sh, zakładając, że masz bezhasłowy dostęp po SSH.
Podsumowanie
Ten artykuł to nie jest żaden rocket science, ale wierzę, że osoby rozpoczynające swoją przygodę z Apache Spark znalazły tu odrobinę wartości.
Trzeba pamiętać, że mimo prostoty i szybkości postawienia klastra, jest też trochę wad. Kolejkowanie FIFO to jedna z nich. Druga to na pewno ograniczona kompatybilność z innymi wersjami Spark’a.
Są też inne opcje takie jak Apache YARN, Apache Mesos, Kubernetes lub Nomad, ale to w innym odcinku 😉.

Jeden komentarz do “Najprostszy sposób na Klaster Apache Spark (Standalone Spark Cluster)”