

Dzięki projektowi Otwarte Dane mamy do dyspozycji źródła udostępnione przez podmioty publiczne. W artykule przygotujemy i wyczyścimy Pojazdy zarejestrowane w Polsce w podziale na województwa za pomocą Python i Pandas.
Dane źródłowe
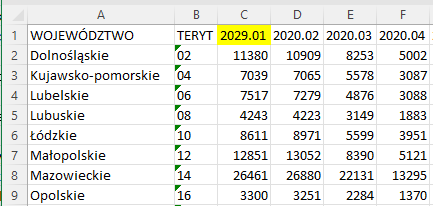
Do dyspozycji mamy dane w formatach csv i xlsx (Excel). Po wstępnej obserwacji widać następujące problemy:
- Niespójne nazwy województw – małe i wielkie litery
- Niespójna liczba kolumn -nie wszędzie występuje kolumna TERYT
- Niespójne nazwy kolumn z miesiącami – miesiące w formie słownej i formacie daty z rokiem + literówki

Wczytanie danych
Z dwóch dostępnych formatów wybrałem xlsx. Poniższy fragment kodu utworzy listę ścieżek dla wszystkich plików tego typu. Czemu wybrałem xlsx, a nie csv? Bez konkretnego powodu.
xlsx_paths = []
for path, subdirs, files in os.walk('..\data'):
for name in files:
if name.endswith('.xlsx'):
xlsx_path = os.path.join(path, name)
print(xlsx_path)
xlsx_paths.append(xlsx_path)
Wynik:
..\data\Pojazdy wg wojewodztw w 2014 r._7282\Pojazdywgwojewodztw20141.xlsx ..\data\Pojazdy wg wojewodztw w 2015 r._2393\Pojazdywgwojewodztw20151.xlsx ..\data\Pojazdy wg wojewodztw w 2016 r._7427\Pojazdywgwojewodztw20161.xlsx ..\data\Pojazdy wg wojewodztw w 2017 r._7272\Pojazdywgwojewodztw20171.xlsx ..\data\Pojazdy wg wojewodztw w 2018 r._16845\Pojazdy_wg_wojew%C3%B3dztw_2018.xlsx ..\data\Pojazdy wg wojewodztw w 2019 r._29466\Pojazdy_wg_województw_2019.xlsx ..\data\Pojazdy wg wojewodztw w 2020 r._29470\Pojazdy_wg_województw_2020.xlsx ..\data\Pojazdy wg wojewodztw w 2021 r._36007\Pojazdy_wg_województw_2021.xlsx ..\data\Pojazdy zarejestrowane w roku 2022 wg wojewodztw_43031\Pojazdy_wg_województw_2022.xlsx
Ścieżki będą podane do metody pandas.ExcelFile.parse.
Przetwarzanie danych
Wszystkie pliki musimy przetworzyć, zapisać Pandas’owych DataFrame, a następnie połączyć w całość. Szablon kodu będzie wyglądać mniej więcej tak:
def parse_xlsx(xlsx_path: str):
df = pd.ExcelFile(xlsx_path).parse()
# TODO: Clean data
return df
df_list = []
for xlsx_path in xlsx_paths:
df_list.append(parse_xlsx(xlsx_path))
full_df = pd.concat(df_list)
W przypadku olbrzymiej liczbie plików można zastanowić się nad zrównolegleniem. Dla tego zbioru nie ma takiej potrzeby. W kolejnych krokach popracujemy nad parse_xlsx
Unifikacja kolumn i nazw województw
Zacznijmy od sprowadzenia nazw kolumn i województw do małych liter. Pozbędziemy się też kolumny teryt. Nie każdy plik xlsx posiada tę kolumnę, dlatego potrzebny jest parametr errors='ignore'.
def parse_xlsx(xlsx_path: str):
df = pd.ExcelFile(xlsx_path).parse()
df.columns= df.columns.str.lower()
df['województwo'] = df['województwo'].str.lower()
df = df.drop(columns=['teryt'], errors='ignore')
# ...
return df
Dodanie kolumny z rokiem
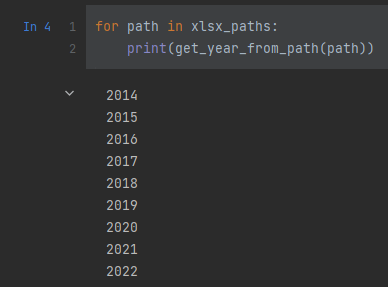
Skąd wziąć rok którego dotyczą dane? Kolumny odpadają. Możemy wykorzystać ścieżkę pliku. Każdy folder ma rok otoczony spacjami. Prosty regex powinien wystarczyć.
import re
def get_year_from_path(file_path: str):
result = re.search(r" (\d{4}) ", file_path)
return result.group(1)
def parse_xlsx(xlsx_path: str):
df = pd.ExcelFile(xlsx_path).parse()
df.columns= df.columns.str.lower()
df['województwo'] = df['województwo'].str.lower()
df = df.drop(columns=['teryt'], errors='ignore')
df['year'] = get_year_from_path(xlsx_path)
# ...
return df
Zamiana NaN na None
W danych znajdują się brakujące wartości. Aby uprościć ewentualne przekształcenia do typów numerycznych zmienimy NaN na None/Null. Celowo nie uzupełniam brakujących danych.
def parse_xlsx(xlsx_path: str):
df = pd.ExcelFile(xlsx_path).parse()
df.columns= df.columns.str.lower()
df['województwo'] = df['województwo'].str.lower()
df = df.drop(columns=['teryt'], errors='ignore')
df['year'] = get_year_from_path(xlsx_path)
df = df.replace(np.nan,None,regex = True)
# ...
return df
Zmiana nazw kolumn
Nazwy kolumn dla miesięcy mają różne konwencje nazewnicze. Narzucimy nową w postaci liczb od 1 do 12.
def parse_xlsx(xlsx_path: str):
df = pd.ExcelFile(xlsx_path).parse()
df.columns= df.columns.str.lower()
df['województwo'] = df['województwo'].str.lower()
df = df.drop(columns=['teryt'], errors='ignore')
df['year'] = get_year_from_path(xlsx_path)
df = df.replace(np.nan,None,regex = True)
new_column_names = ['voivodeship'] + list(range(1,13)) + ['year']
df.columns = new_column_names
# ...
return df

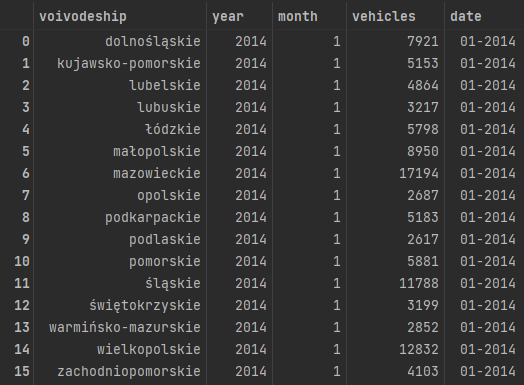
Zmiana kolumn w wiersze (UNPIVOT)
Każdy wiersz zawiera do 12 wartości. Ciężko będzie coś takiego zwizualizować. Przydała by się kolumna dla liczby zarejestrowanych aut oraz kolumna dla miesięcy. Wykorzystamy do tego pandas.melt.
def parse_xlsx(xlsx_path: str):
df = pd.ExcelFile(xlsx_path).parse()
df.columns= df.columns.str.lower()
df['województwo'] = df['województwo'].str.lower()
df = df.drop(columns=['teryt'], errors='ignore')
df['year'] = get_year_from_path(xlsx_path)
df = df.replace(np.nan,None,regex = True)
new_column_names = ['voivodeship'] + list(range(1,13)) + ['year']
df.columns = new_column_names
df = df.melt(id_vars =['voivodeship', 'year'], value_vars =list(range(1,13)), var_name ='month', value_name ='vehicles')
return df
Ostatnie szlify
Pole z datą
Planuje wrzucić dane do Elasticsearch’a. Przyda się kolumna pod @timestamp.
full_df['date'] = full_df['month'].astype(str).str.zfill(2) + "-" + full_df['year'].astype(str)
Kolejna literówka
Po wrzuceniu CSV’ki do Elastic Stack zauważyłem kolejną literówkę: warmińskie != warmińsko. Jak widać, etap analizy danych nie zwalnia nas z etapu czyszczenia – bez tego będzie ciężko 😉.

full_df.voivodeship = full_df.voivodeship.apply(lambda x: 'warmińsko-mazurskie' if 'warmińskie-mazurskie' in x else x)
Podsumowanie
- Jakość danych jest kluczowa i zależy od niej jakość analiz i modeli.
- Część błędów zauważymy dopiero na etapie analizy.
- W następnym artykule zobaczymy co przedstawiają omawiane dane.
- Temat artykułu nie jest jakimś “rocket science”, ale całkiem przyjemnie pracowało mi się przy otwartych danych 😁.
Repozytorium
https://github.com/zorteran/cleaning-data-with-pandas

Jeden komentarz do “Jak Wyczyścić Dane w Python Pandas – Pojazdy zarejestrowane w Polsce”