

Elastic wprowadził mechanizm Runtime fields, a Facebook’owi przydarzył się wyciek. Jest to dobry pretekst, aby przetestować jedno i przyjrzeć się drugiemu 😁. Szczegóły o wycieku znajdziesz w artykule Niebezpiecznika.
Wczytanie danych
Struktura dokumentu
Dane są w formacie CSV. Poniżej jeden z wierszy. Oczywiście zanonimizowany.
48123456789:123456789012345:Jan:Kowalski:male:::::4/21/2019 12-00-00 AM::::False:False:4/26/2019 6-18-55 PM:9/2/2010 12-00-00 AM
Separatorem jest :, ale nie znamy nazw kolumn. Te oczywiste zdefiniujemy w Logstash’u, a resztę postaramy się określić już w Kibanie.
Logstash
Pipeline składa się z wejścia w postaci pliku, filtru który wydzieli pola z każdego wiersza oraz wyjścia do elasticsearch’a i konsoli. W przypadku konsoli wykorzystany jest kodek dots. Każdy przetworzony dokument reprezentowany jest na konsoli w postaci kropki. Jest to prosty sposób śledzenia postępów Logstasha. Można go tez łączyć z komendą pv.
Nieznane kolumny nazwałem po prostu col + numer, w parze z parametrem skip_empty_columns.
Plik z definicją pipeline’a możemy uruchomić bezpośrednio w konsoli używając poniższej komendy. Ściezka Logstash’a odpowiada domyślnej ścieżce instalacji.
/usr/share/logstash/bin/logstash -f /path/to/config/poland.conf --path.data /tmp/path_for_temp_files
input {
file {
path => "/path/to/file/Poland.txt"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
skip_header => false
separator => ":"
quote_char => ":"
skip_empty_columns => true
columns => ["phone","id","first_name","last_name","sex","col5","col6","col7","col8","col9","col10","col11","col12","col13","col14","col15","col16","col17","col18","col19"]
}
}
output {
stdout{ codec => dots }
elasticsearch {
hosts => ["http://192.168.1.17:9200"]
user => "user"
password => "password"
index => "poland"
}
}
Eksploracja danych
Indeks w Elasticsearch został utworzony dynamicznie. Index pattern w Kibana należy dodać ręcznie. Nie są to dane typu szeregi czasowe, więc nie ma pola odpowiadającego za czas.
W module Discovery, po lewej stronie widzimy dostępne pola i top wartości na podstawie próbki 500 rekordów. Jest to dobry sposób na wstępne określenie nazw kolumn.
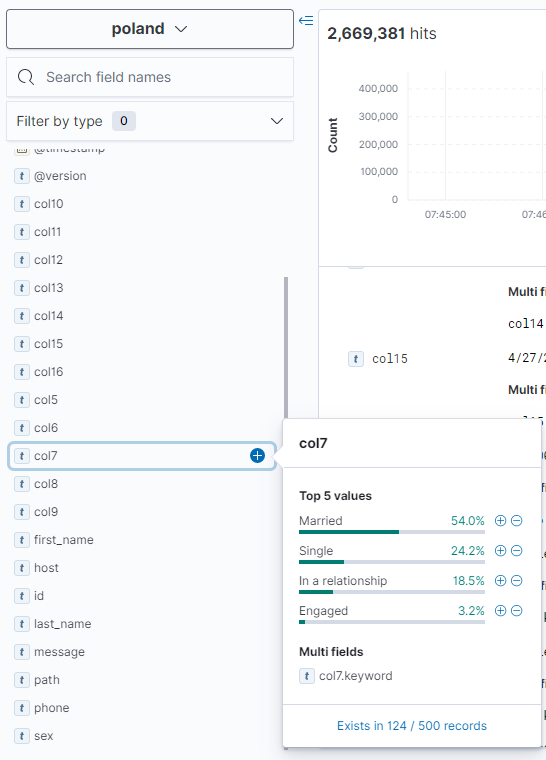

Znajdziemy 3 kolumny z datami. W jednej z nich nie zawsze występuje rok. Jest to kandydat do daty urodzin. Jest to nadal moduł Discovery, ale z dodanymi kolumnami.

Niestety na tym etapie nie możemy zwizualizować dat na wykresie. Dane dodaliśmy korzystając domyślnych ustawień indeksu i dynamicznych pól. Format daty w kolumnach jest niezgodny z domyślnym dla typu date, więc Elasticsearch zidentyfikował pole jako text/keyword.
Przetworzenie danych
Idealnie, jakby wszystkie dane indeksowane do Elasticsearch były już wyczyszczone, wzbogacone i zdenormalizowane. Elasticsearch nie lubi JOIN’ów i posiada naturę Schema on write. Posiada jednak szereg mechanizmów, którymi możemy zmienić dane które już w nim są.
Ingest Pipeline
Naturalnym sposobem przetwarzania danych przed zaindeksowaniem w Elasticsearch jest wykorzystanie Logstasha. Niestety, gdy z niego korzystaliśmy nie wiedzieliśmy jak wyglądają dane. Moglibyśmy poprawić pipeline i zrobić to jeszcze raz, ale dla odmiany wykorzystamy mechanizm Ingest Pipelines. Przypomina on to co robi Logstash, ale możemy go użyć po stronie klastra, a co najważniejsze, również podczas reindeksowania danych.
Poniżej znajduje się definicja ingest pipeline’a o nazwie poland_to_fb_pl_reindex. Wykonuje proste operacje usunięcia i zmiany nazwy pola.
PUT _ingest/pipeline/poland_to_fb_pl_reindex
{
"processors": [
{
"rename": {
"field": "col5",
"target_field": "city_in",
"ignore_failure": true,
"ignore_missing": true
}
},
{
"rename": {
"field": "col6",
"target_field": "city_from",
"ignore_failure": true,
"ignore_missing": true
}
},
{
"rename": {
"field": "col7",
"target_field": "marital_status",
"ignore_failure": true,
"ignore_missing": true
}
},
{
"rename": {
"field": "col8",
"target_field": "work",
"ignore_failure": true,
"ignore_missing": true
}
},
{
"rename": {
"field": "col9",
"target_field": "date_1",
"ignore_failure": true,
"ignore_missing": true
}
},
{
"rename": {
"field": "col10",
"target_field": "email",
"ignore_failure": true,
"ignore_missing": true
}
},
{
"rename": {
"field": "col11",
"target_field": "birthsday",
"ignore_failure": true,
"ignore_missing": true
}
},
{
"rename": {
"field": "col12",
"target_field": "year",
"ignore_failure": true,
"ignore_missing": true
}
},
{
"remove": {
"field": "col13",
"ignore_failure": true,
"ignore_missing": true
}
},
{
"remove": {
"field": "col14",
"ignore_failure": true,
"ignore_missing": true
}
},
{
"rename": {
"field": "col15",
"target_field": "date_2",
"ignore_failure": true,
"ignore_missing": true
}
},
{
"rename": {
"field": "col16",
"target_field": "account_date",
"ignore_failure": true,
"ignore_missing": true
}
}
]
}
Reindex
Mechanizm Reindex pozwala na wczytanie i zapis danych z jednego do drugiego indeksu. Możemy go porównać z grubsza do INSERT INTO table2 SELECT * FROM table1.
W pipeline nie poruszyliśmy problemu formatu daty. Zrobimy to po stronie nowego indeksu definiując odpowiedni format. Celowo nie definiuje reszty pól (z lenistwa).
PUT fb_pl
{
"mappings": {
"properties": {
"date_1": {
"type": "date",
"format": [
"M/d/yyyy h-mm-ss a"
]
},
"date_2": {
"type": "date",
"format": [
"M/d/yyyy h-mm-ss a"
]
}
}
}
}
Teraz możemy wykonać reindex korzystając z wcześniej utworzonego pipeline’a. Parametr slices odpowiada za zrównoleglenie operacji, natomiast wait_for_completion za to czy operacja jest asynchroniczna.
POST _reindex?slices=auto&wait_for_completion=false
{
"source": {
"index": "poland"
},
"dest": {
"index": "fb_pl",
"pipeline": "poland_to_fb_pl_reindex"
}
}
Eksploracja danych
Teraz możemy zwizualizować rozkład dat w polach date_1 oraz date_2. Osią X będzie czas z wyżej wymienionych pól, a na osi Y liczba dokumentów.
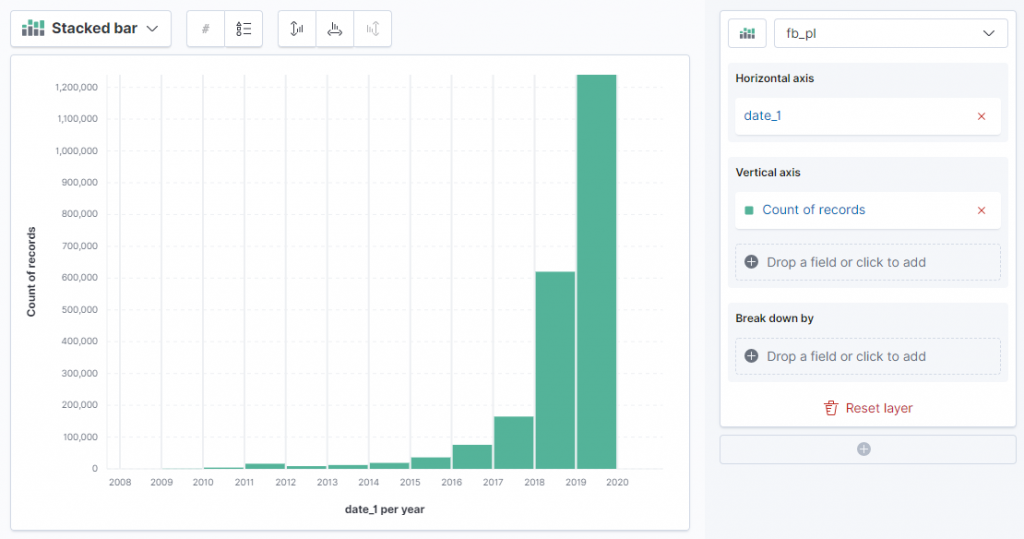
date_1 wygląda na czas ostatniego zalogowania się.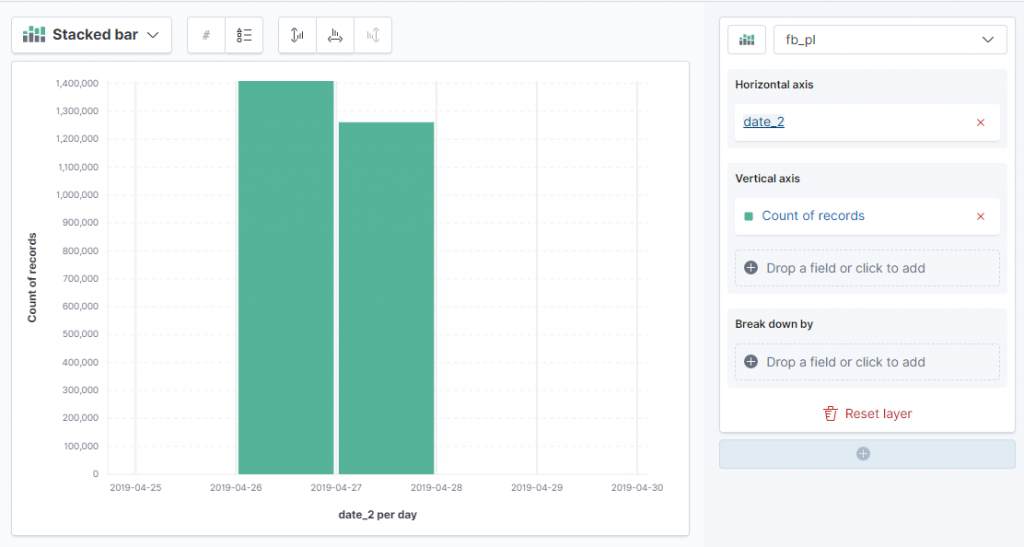
date_2 to dwie wartości. Ciężko powiedzieć co oznacza.Tabela z najczęściej występującymi pracodawcami pokazuje niedoskonałość danych, czyli brak normalizacji. Frazy Retired i emeryt oznaczają to samo, ale pogrupowanie wszystkich fraz to sporo pracy. W następnym kroku skupimy się na prostym mechanizmie, który sprowadzi wartości do małych liter. Zawsze coś 😊.
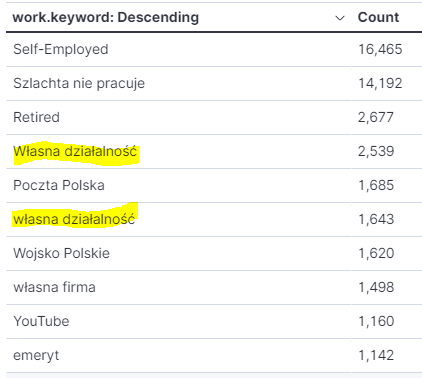
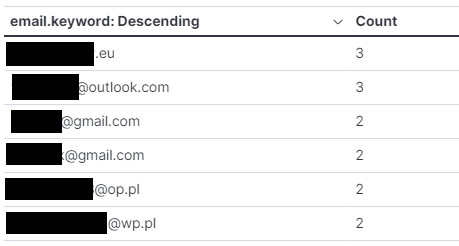
Prosta agregacja maili pokazuje, że są konto może mieć więcej niż jeden numer telefonu. Przy okazji widzimy potencjał pogrupowania po domenie, jeśli uda się wyłuskać ją z wartości adresu email.
Runtime fields
Elasticsearch jest to rozwiązanie które faworyzuje czas odczytu kosztem czasu indeksowania. Dzięki podejściu Schema on write każde pole dokumentu może być odpowiednio przetworzone i zoptymalizowane pod wyszukiwanie. Niestety jest to podejście mniej elastyczne niż Schema on read, gdzie mamy możliwość dynamicznego dostosowania pól do naszych potrzeb.
Właśnie dlatego od wersji 7.11 mamy do dyspozycji Runtime fields. Jest to mechanizm pozwalający na definiowane dynamicznych pól, które wartości są wynikiem przypisanego skryptu. Zyskujemy na elastyczności kosztem szybkości wyszukiwania, no i nie jest to do końca nowość. Wcześniej mieliśmy możliwość tworzenia Scripted fields na poziomie zapytania Elasticsearch oraz Scripited field na poziomie index pattern w Kibana.
Efektem poniższych zapytań będą nowe pola w index pattern w Kibanie. Z punktu widzenia użytkownika nie widać różnicy czy pole jest “standardowe”, czy typu runtime.
Birthsday Month & year
Pole birthsday ciężko dopasować do daty, ponieważ nie wszystkie dokumenty mają rok. Możemy natomiast wyłuskać miesiąc i rok z tego pola. Samo pole nie zawsze występuje, więc musimy się przed tym zabezpieczyć w skrypcie.
PUT fb_pl/_mapping
{
"runtime": {
"birthsday_month": {
"type": "long",
"script": {
"source": """
try {
long month = Long.parseLong(doc['birthsday.keyword'].value.toString().splitOnToken('/')[0]);
emit(month)
}
catch(Exception e){
}
"""
}
}
}
}
PUT fb_pl/_mapping
{
"runtime": {
"birthsday_year": {
"type": "long",
"script": {
"source": """
try {
long year = Long.parseLong(doc['birthsday.keyword'].value.toString().splitOnToken('/')[2]);
emit(year)
}
catch(Exception e) {
}
"""
}
}
}
}
W standardowym zapytaniu HTTP musimy wskazać nazwy pól runtime, które chcemy dostać w odpowiedzi.
POST fb_pl/_search
{
"_source": "birthsday",
"fields" : ["birthsday_month","birthsday_year"],
"query": {
"exists": {
"field": "birthsday.keyword"
}
}
}
Co daje nam:
...
"hits" : [
{
"_index" : "fb_pl",
"_type" : "_doc",
"_id" : "xXVvAnkBpPGxMGvREbwU",
"_score" : 1.0,
"_source" : {
"birthsday" : "07/13"
},
"fields" : {
"birthsday_month" : [
7
]
}
},
{
"_index" : "fb_pl",
"_type" : "_doc",
"_id" : "yXVvAnkBpPGxMGvREbwU",
"_score" : 1.0,
"_source" : {
"birthsday" : "01/02/1990"
},
"fields" : {
"birthsday_year" : [
1990
],
"birthsday_month" : [
1
]
}
},
...
Work normalized
PUT fb_pl/_mapping
{
"runtime": {
"work_normalized": {
"type": "keyword",
"script": {
"source": """
try {
emit(doc['work.keyword'].value.toString().trim().toLowerCase())
}
catch(Exception e) {
}
"""
}
}
}
}
Email domain
PUT fb_pl/_mapping
{
"runtime": {
"email_domain": {
"type": "keyword",
"script": {
"source": """
try {
def email = doc["email.keyword"].value;
def atPosition = email.indexOf("@");
def domain = email.substring(atPosition+1, email.length());
emit(domain);
}
catch(Exception e) {
}
"""
}
}
}
}
Analiza
Pracodawcy
Na dość wysokich pozycjach są tacy “pracodawcy” jak szlachta nie pracuje, wyższa szkoła robienia hałasu oraz ‘wyższa szkoła melanżu .‘. Skąd kropka pod koniec? Nie wiem.
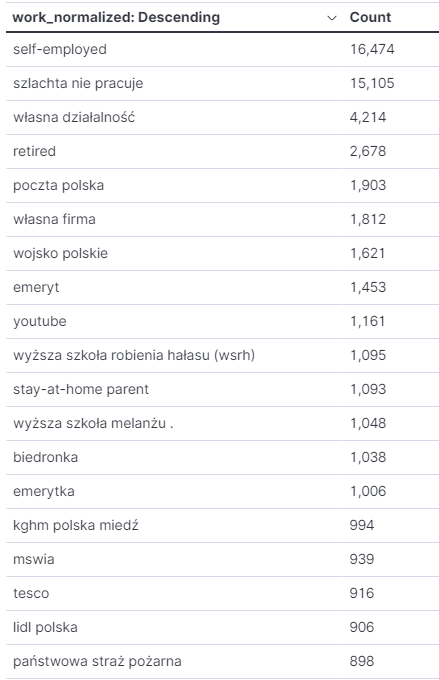
Wyciek dotyczył tylko kont posiadających numery telefonu. Pewnie właśnie myślisz, że większość osób z wycieku to “szlachta” 😉. Spokojnie. Po uwzględnieniu osób, które nie wpisały pracodawcy i wyświetleniu wartości procentowej, okazuje się, że nie jest z nami tak źle.

Zagraniczne numery telefonu
Niestety na podstawie dostępnych danych nie możemy zweryfikować ile osób jest z Polski, ale używa zagranicznego numeru telefonu. Wszystkie zaczynają się od kierunkowego 48.

Jakie roczniki najczęściej korzystają z Facebook’a?
A raczej który rocznik najczęściej przyznaje się do swojego roku urodzenia 😁. Wychodzi na to, że roczniki 1991-1997.
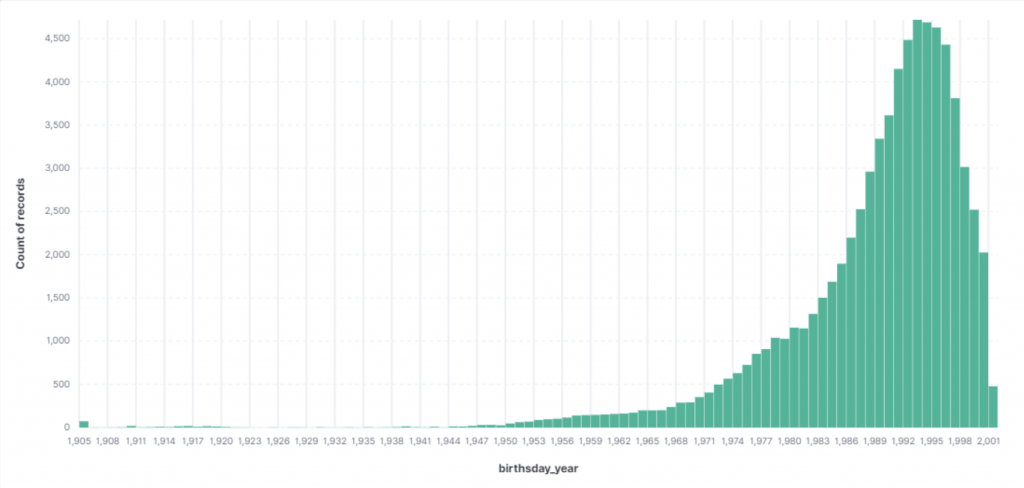
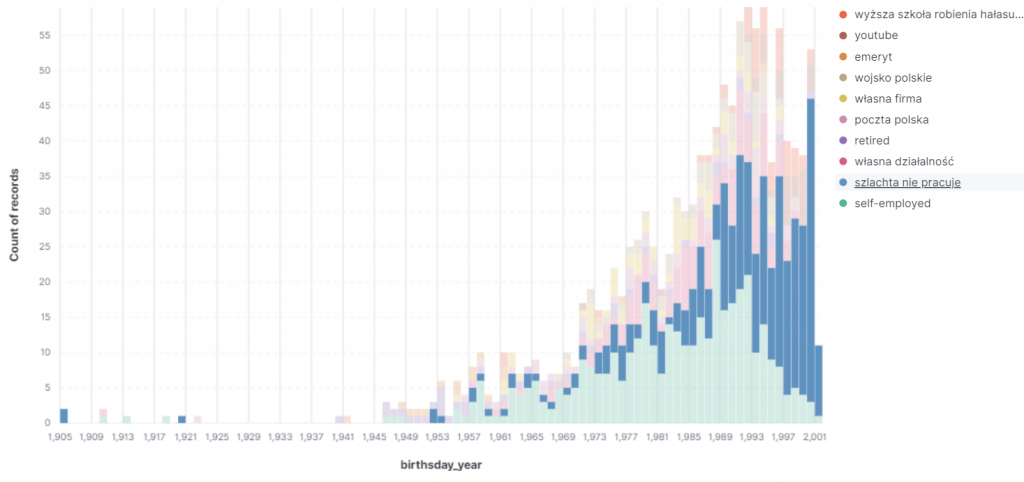
Gdy spojrzymy na histogram dla najpopularniejszych pracodawców okaże się, że najmłodsi są najbardziej “szlacheccy”.
Po polu date_month nie spodziewałem się spektakularnych wniosków i tak właśnie jest.
Najbardziej szlacheckie miasto
Pozornie może nam się wydawać, że najbardziej “szlacheckim” miastem jest Warszawa, a za nim Kraków i Wrocław. Nic bardziej mylnego.
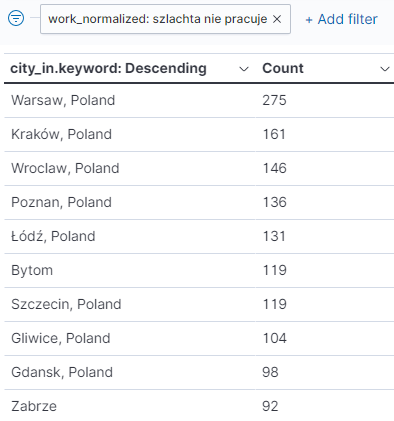
“Szlachta” rozsiana jest po całym kraju, więc bardziej odpowiednie wydaje się być porównywanie powiatów lub województw. Miejscowości goszczących “szlachtę” jest aż 4673.
POST fb_pl/_search
{
"size": 0,
"query": {
"match": {
"work_normalized": "szlachta nie pracuje"
}
},
"aggs": {
"number_of_cities": {
"cardinality": {
"field": "city_in.keyword"
}
}
}
}
Najpopularniejsze domeny pocztowe
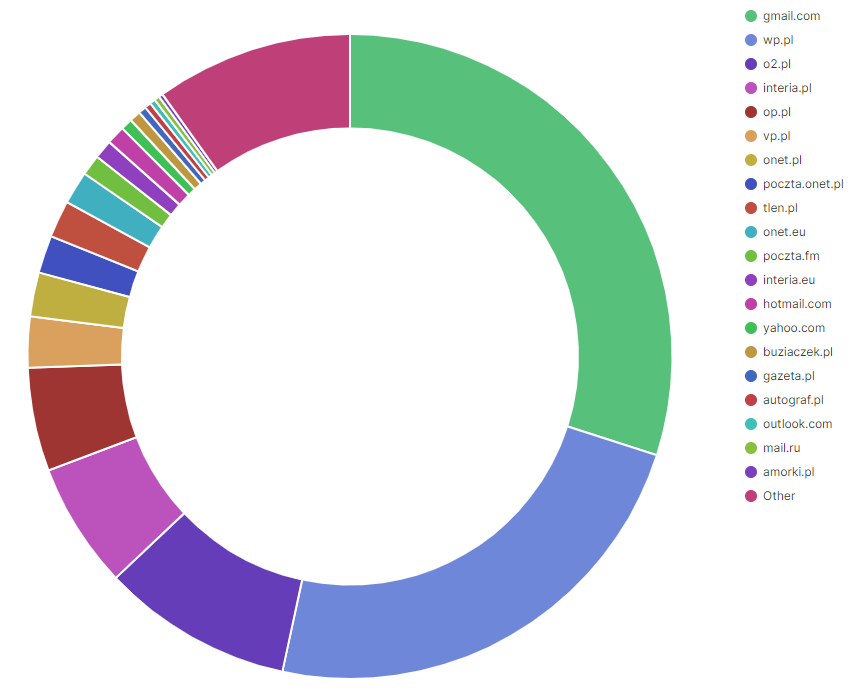
Na pierwszym miejscu jest gmail.com, a zaraz za nim wp.pl. Całkiem wysoko jest mail.ru 🤔. Sporo domen jest od związana z onet.pl.
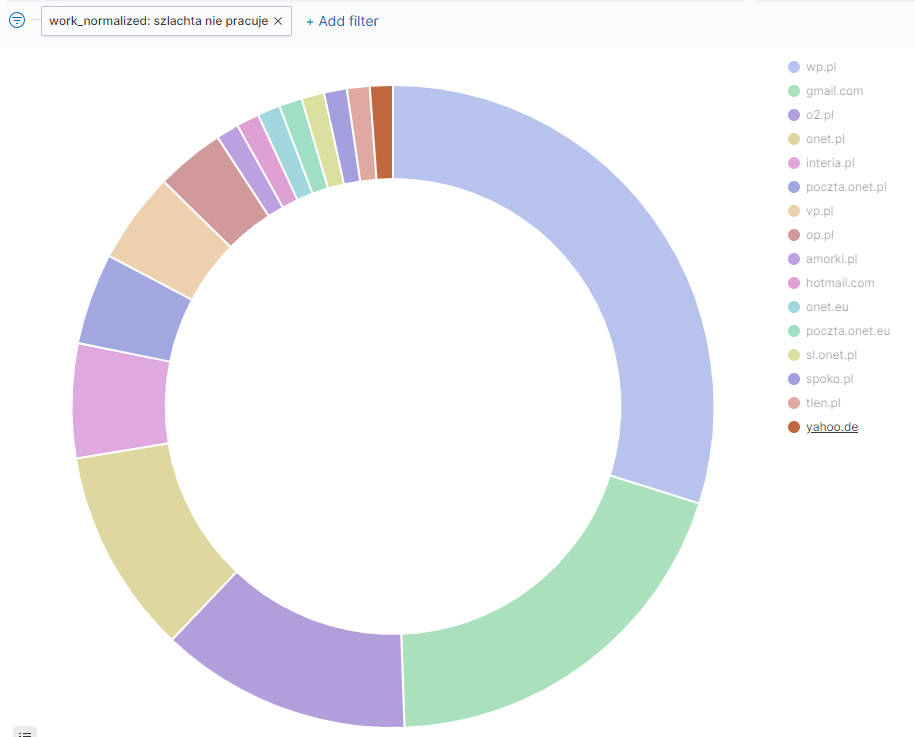
Co ciekawe “szlachta” nie korzysta aż z tylu dostawców usługi poczty elektronicznej. Widzimy też, że część z nich posiada niemieckie korzenie korzystając z yahoo.de.
Szlachecki rocznik
Elasticsearch umożliwia wyszukiwanie anomalii i nietypowych wartości pól między innymi za pomocą agregacji Significant Terms. Zasada jej działania polega z grubsza na porównaniu dwóch zbiorów: foreground, dokumenty w filtrze i/lub kubełku i background, reszta dokumentów w całym indeksie lub kubełku.
Pole birthsday_year utworzyłem jako typ long. Significant Terms działą tylko z typem keyword. Runtime field nic nie waży, więc bez kosztowo mogę dodać kolejne pole.
PUT fb_pl/_mapping
{
"runtime": {
"birthsday_year.keyword": {
"type": "keyword",
"script": {
"source": """
try {
long year = Long.parseLong(doc['birthsday.keyword'].value.toString().splitOnToken('/')[2]);
emit(year.toString())
}
catch(Exception e) {
}
"""
}
}
}
}
Significant Terms możemy użyć w większości wizualizacji. Niestety agregacja ta w parze z Runtime fields jest bardzo wolna. W kibanie nie mogłem doczekać się wizualizacji, a na standardowe zapytanie HTTP dostawałem timeout.
POST fb_pl/_search
{
"size": 0,
"query": {
"match": {
"work": "szlachta nie pracuje"
}
},
"aggs": {
"unusual_birthsday_year": {
"significant_terms": {
"field": "city_in.keyword"
}
}
}
}
{"statusCode":502,"error":"Bad Gateway","message":"Client request timeout"}
Koniecznie było wykorzystanie Async serach, czyli asynchroniczne podejście do wyszukiwania i agregacji. Wystarczy zmienić _serach na _async_search. Co ciekawe zapytanie wykonywało się prawie 8 minut. Dla standardowych pól są to najczęściej milisekundy.
GET _async_search/FnNEbDJIYndsUjlXOFR4emNNekJjZVEgSXZ5NlpBQkRSWmFwMVdCMEc0NXZNdzoyMjI4Nzg4ODM=
{
"id" : "FnNEbDJIYndsUjlXOFR4emNNekJjZVEgSXZ5NlpBQkRSWmFwMVdCMEc0NXZNdzoyMjI4Nzg4ODM=",
"is_partial" : false,
"is_running" : false,
"start_time_in_millis" : 1620044307679,
"expiration_time_in_millis" : 1620476307679,
"response" : {
"took" : 471092,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"unusual_birthsday_year" : {
"doc_count" : 15105,
"bg_count" : 2669381,
"buckets" : [
{
"key" : 2000,
"doc_count" : 43,
"score" : 0.007830686648180448,
"bg_count" : 2026
},
{
"key" : 2001,
"doc_count" : 10,
"score" : 0.001790703115402477,
"bg_count" : 477
},
{
"key" : 1999,
"doc_count" : 24,
"score" : 0.001084243918904845,
"bg_count" : 2521
},
{
"key" : 1998,
"doc_count" : 24,
"score" : 6.462597874566355E-4,
"bg_count" : 3015
},
{
"key" : 1996,
"doc_count" : 27,
"score" : 1.3778801749659235E-4,
"bg_count" : 4430
},
{
"key" : 1974,
"doc_count" : 4,
"score" : 3.2790804064010336E-5,
"bg_count" : 629
},
{
"key" : 1976,
"doc_count" : 5,
"score" : 1.1877936046728303E-5,
"bg_count" : 853
}
]
}
}
}
}
Okazuje się, że nietypowym pod kątem “szlachty” rocznikiem jest 2000. Grupa w ta jest wyjątkowo liczna.
Podsumowanie
Runtime fields to ciekawy i przydatny mechanizm. Pozwala dostosować dane do potrzeb analitycznych, a dodane pola nie zabierają miejsca na dyskach. Trzeba mieć świadomość, że wszystkie operacje wykorzystujące te pola będą wolniejsze. Zalety tego mechanizmu widzą między innymi twórcy projektu ElastiFlow. Ograniczenie wielkości danych o 44% to całkiem sporo.
Bawiąc się danymi problem z szybkością zapytań odczułem głównie wykorzystując Significant Terms. Przy tworzeniu standardowych wizualizacji musiałem trochę poczekać, ale kolejne próby wizualizacji były już szybsze. Zgaduję, że jest to kwestia cache’owania wartości. Należy jednak pamiętać, ze były to statyczne dane o wielkości około 1.4 GB. W dzisiejszych czasach jest to tak naprawdę śladowa ilość.
Kurs Elastic Stack
Jeśli zaciekawił Cię temat Elastic Stack (Elasticserach, Logstash, Kibana, Beats) zapraszam do zapoznania się z agendą mojego kursu. 12.05.2021 planuję kolejne otwarcie.
Tutaj znajdziesz 3 darmowe lekcje, gdzie omawiam jak postawić lokalny klaster oraz Kibane.
