

Chcemy, aby nasze aplikacje w Apache Spark wykorzystywały wszystkie przydzielone zasoby. Niestety nie jest to takie proste. Rozproszenie obliczeń niesie za sobą koszty zarządzania zadaniami, a same zadania mają wobec siebie zależności. Z jednej strony ogranicza nas CPU (szybkość obliczeń), z drugiej strony dyski i sieć. MapReduce poświęciłem dedykowany materiał wideo. W artykule dowiesz się jak w 2 prostych krokach poprawić utylizację zasobów w Apache Spark.
Prosta aplikacja
Przyjrzyjmy się strukturze typowej aplikacji w Apache Spark.
val students = spark.read
.format("...")
.option("table", "some_students_table")
.load()
val filteredStudents = students
.filter("...")
studentsAfterSomeTransformations.write
.format("...")
.option("collection", "some_collection")
.save()
Najpierw określamy źródło danych, następnie wykonujemy na nim pewne operacje, aby finalnie zapisać wyniki. Wszystkie transformacje w Spark’u są lewnie, więc obliczenia rozpoczną się dopiero przy operacji zapisu.
Nie taka prosta aplikacja
Zerknijmy teraz na szablon trochę bardziej zaawansowanej aplikacji. Załóżmy, że mamy dwa lub więcej źródeł. Dodatkowo dane przekształcamy i agregujemy po różnych encjach.
val students = spark.read
.format("...")
.option("table", "some_students_table")
.load()
val groups = spark.read
.format("...")
.option("table", "some_groups_table")
.load()
val teachers = spark.read
.format("...")
.option("table", "some_teachers_table")
.load()
val filteredStudents = students
.filter("...")
val filteredGroups = groups
.filter("...")
val filteredteachers = teachers
.filter("...")
val allInOne = filteredGroups
.join(filteredStudents,...)
.join(filteredteachers,...)
.transform(...)
.transform(...)
.transform(...)
// allInOne.cache()
// OR
// allInOne.persist(...)
val studentsStats = allInOne
.groupBy(...)
.agg(...)
val groupsStats = allInOne
.groupBy(...)
.agg(...)
val teachersStats = allInOne
.groupBy(...)
.agg(...)
writeToStatsTable(studentsStats, "my_stats_collection")
writeToStatsTable(groupsStats, "my_stats_collection")
writeToStatsTable(teachersStats, "my_stats_collection")
...
def writeToStatsTable(stats: DataFrame, table: String): Unit = {
stats.write
.format("...")
.option("collection", table)
.save()
}
Sprawa trochę się pokomplikowała. Dane z wielu źródeł są pobierane, złączane i przekształcane. Jest to dobry moment na cache/persist (linia 32-34), aby nie wykonywać tych samych kroków dla każdej operacji zapisu.
Skupmy się na liniach 48-50. Widać tu trochę powtórzeń (copy&paste) gdzie róźni się tylko jedna zmienna. Spróbujmy to trochę poprawić.
Seq( studentsStats, groupsStats, teachersStats ).foreach(writeToStatsTable(_, "my_stats_collection"))
Od razu jakoś tak ładniej 😊. Pod katem wydajności jednak nie ma zmian. Kod wykonywany jest nadal sekwencyjnie przez Driver.
Krok 1 – Parallel Collections
W Scali mamy możliwość zmiany kolekcji sekwencyjnej, na taką obsługiwaną równolegle. W naszym przypadku wystarczy dodać .par
Seq( studentsStats, groupsStats, teachersStats ).par.foreach(writeToStatsTable(_, "my_stats_collection"))
Krok 2 – Zmiana FIFO na FAIR
To jednak nie wystarczy. Domyślnie zadania w Spark’u wykonywane są sekwencyjnie (kolejka FIFO). Szczegóły znajdziesz tutaj. Możemy to zmienić w kodzie lub konfiguracją spark-submit
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.scheduler.mode", "FAIR")
val sc = new SparkContext(conf)
Porównanie wyników
W artykule posługiwałem się czymś w rodzaju pseudo kodu. Poniżej możesz zobaczyć wykres utylizacji CPU dla dwóch aplikacji. W jednej wykorzystałem .par przy zapisie, reszta kodu jest identyczna.
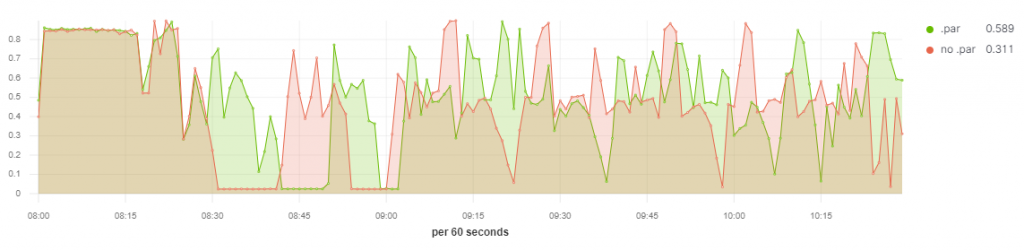
Screenshot jest z wizualizacji TSVB w Kibana, a do zbierania metryk wykorzystałem Metricbeat. Są to dwie funkcje, jedna z nich ma ustawiony offset tak, aby pokrywał się moment uruchomienia aplikacji Apache Spark. Zadania były odpalane na 4-nodowym klastrze.
Wnioski:
- W czasie 8:30
.parnadal pracuje, gdzieno .parrobi “przerwę” na około 10 minut. - Widać różnicę w sumarycznym porównania zużycia CPU –
.par0.589 vsno .par0.311. - Nie widać tego po wykresie, ale zadanie z
.parkończy się około 10:07. Potem uruchomione zostało kolejne zadanie z DAG’a w Apache Airflow. Zadanieno .parzakończyło się dopiero około 10:30. Jest to ponad 15% poprawa czasu wykonania aplikacji.
Podsumowanie
Niewielką zmienną w kodzie i konfiguracji udało się zmniejszyć czas potrzebny na wykonanie aplikacji. Oczywiście wyniki mogą się różnić zaleznie od poziomu skomplikowania aplikacji.
Warto optymalizować aplikacje Apache Spark. Czas to pieniądz, a w świecie chmury publicznej, dosłownie 😁.

Jeden komentarz do “Apache Spark – 2 Kroki do Lepszej Utylizacji Zasobów”