

Kafka Connect to część platformy Apache Kafka. Służy do łączenia Kafki z zewnętrznymi serwisami takimi jak systemy plików lub bazy danych. W artykule dowiesz się jaki problem rozwiązuje i jak ją uruchomić.
Dlaczego Kafka Connect?
Apache Kafka wykorzystywana jest w architekturze mikroserwisów, agregacji logów, Change data capture (CDC), integracji, platforma do przetwarzania strumieniowego i warstwa akwizycji danych do Data Lake‘a. Niezależnie do czego wykorzystujesz Kafkę, dane płyną ze źródła (source) i trafiają do ujścia (sink).
Implementacja konsumenta lub producenta Apache Kafka zgodnie ze sztuką wymaga czasu i wiedzy. Rzecz w tym, że źródła i ujścia często powtarzają się. Wiele firm zapisuje dane z Kafki do HDFS/S3 i Elasticsearch. A gdyby tak napisać takie połączenie raz a porządnie?
Nie ma sensu wymyślać koła na nowo. Kafka Connect rozwiązuje ten problem. Jest to platforma do łączenia Kafki z zewnętrznymi komponentami. Za pomocą systemu konektorów, możemy elastycznie konfigurować wejścia/wyjścia do /z kolejki. Może działać samodzielnie i w trybie rozproszonym, dzięki czemu uzyskujemy rozproszoną, skalowalną, odporną na awarię platformę o niskiej barierze wejścia.
Alternatywy
Alternatywy, które przychodzą mi do głowy to:
Konektory
Konektory znajdziesz na stronie Confluent Hub. Dostępne są darmowe jak i płatne, dostępne w ramach platformy Confluent. Przykładowo: Konektor do Cassandry jest dostępny w wersji płatnej (od Confluent), ale jest też wersja darmowa od DataStax. Jeśli nie znalazłeś gotowego rozwiązania, można napisać swój konektor.
Środowisko
Standardowo, wykorzystany jest tu Docker. W tym przypadku Kafka, Zookeeper i Minio są w postaci kontenerów. Kafka Connect będzie włączane na maszynie hosta. Jest częścią Apache Kafka, więc wystarczy ściągnąć i rozpakować binarkę. Obsługę Kafki możemy ułatwić sobie za pomocą narzędzia Conduktor.
version: '2'
services:
zookeeper:
image: 'bitnami/zookeeper:3'
ports:
- '2181:2181'
volumes:
- 'zookeeper_data:/bitnami'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: 'bitnami/kafka:2'
ports:
- '9092:9092'
- '29092:29092'
volumes:
- 'kafka_data:/bitnami'
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,PLAINTEXT_HOST://:29092
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
depends_on:
- zookeeper
minio:
image: 'bitnami/minio:latest'
ports:
- '9000:9000'
environment:
- MINIO_ACCESS_KEY=minio-access-key
- MINIO_SECRET_KEY=minio-secret-key
volumes:
zookeeper_data:
driver: local
kafka_data:
driver: local
Tryb Standalone – Zapis do pliku
Apache Connect możemy uruchomić w dwóch trybach: Standalone i Distributed. Ten pierwszy służy do testowania i deweloperki. Aby go uruchomić potrzebne są pliki konfiguracyjne.
bootstrap.servers=localhost:29092 key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=org.apache.kafka.connect.storage.StringConverter offset.storage.file.filename=/tmp/connect.offsets
Key i value converter określają format w jakim Kafka ma odczytać/zapisać dane.
name=standalone-file-sink connector.class=FileStreamSink tasks.max=1 file=output.txt topics=standalone-test
Pola wydają się oczywiste. Poniżej GIF z wykonania.
kafka_2.13-2.6.0/bin/connect-standalone.sh connect-standalone.properties connect-file-sink.properties
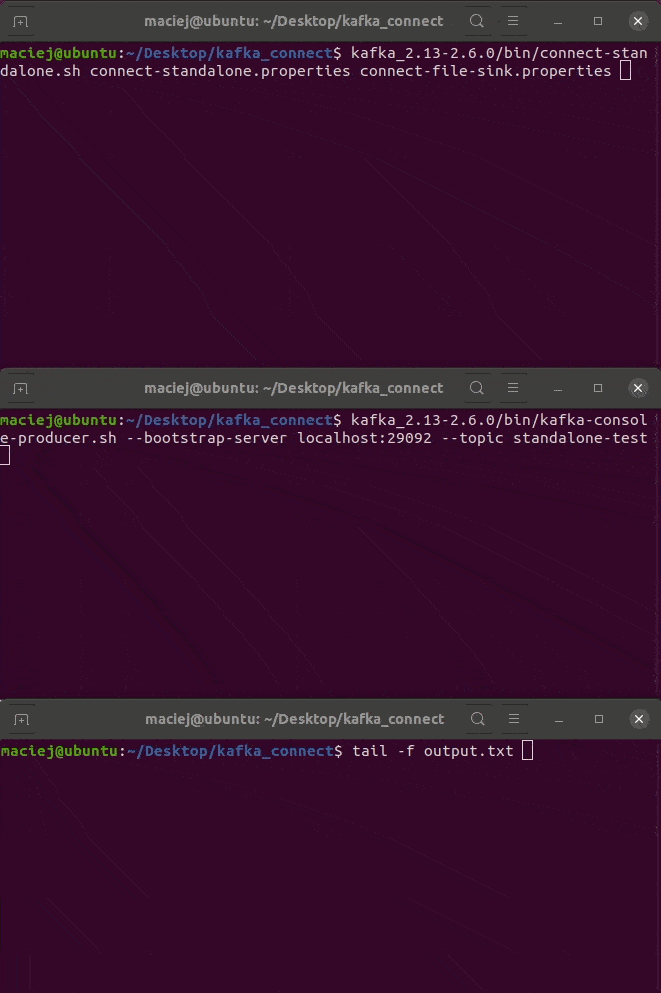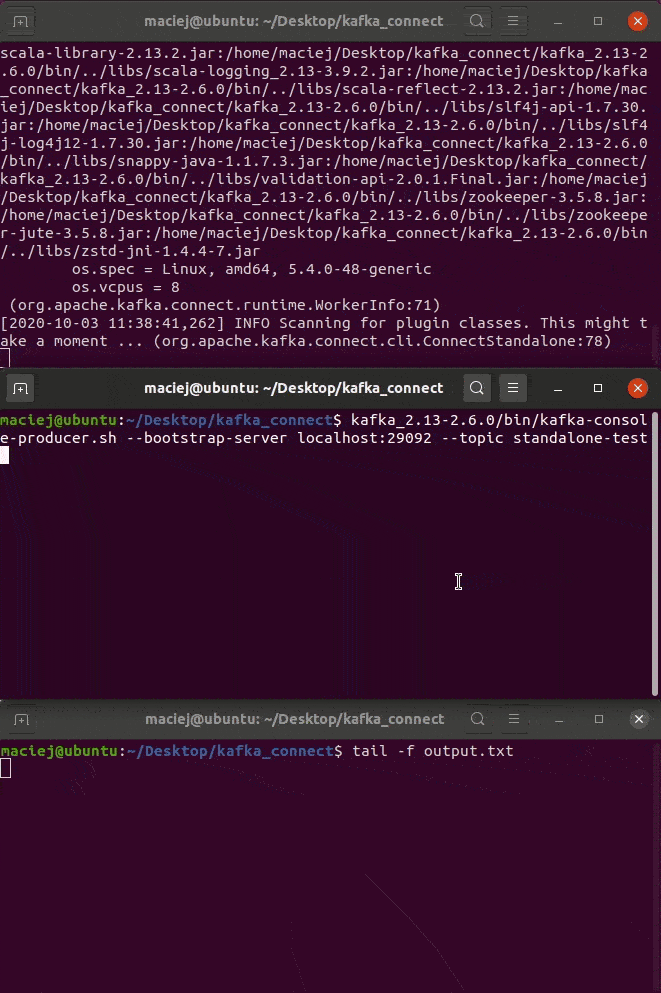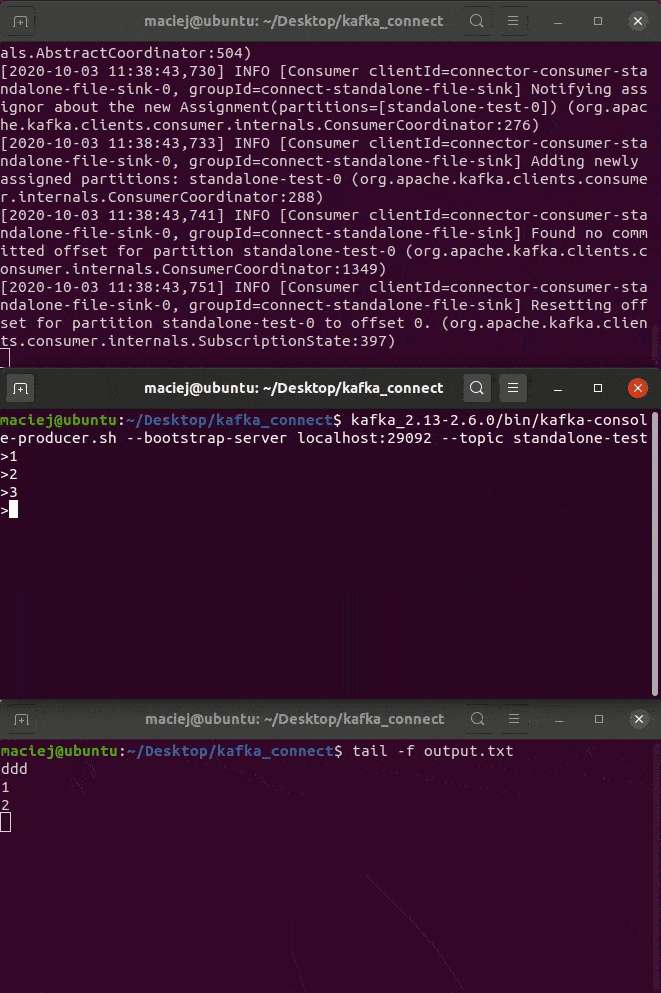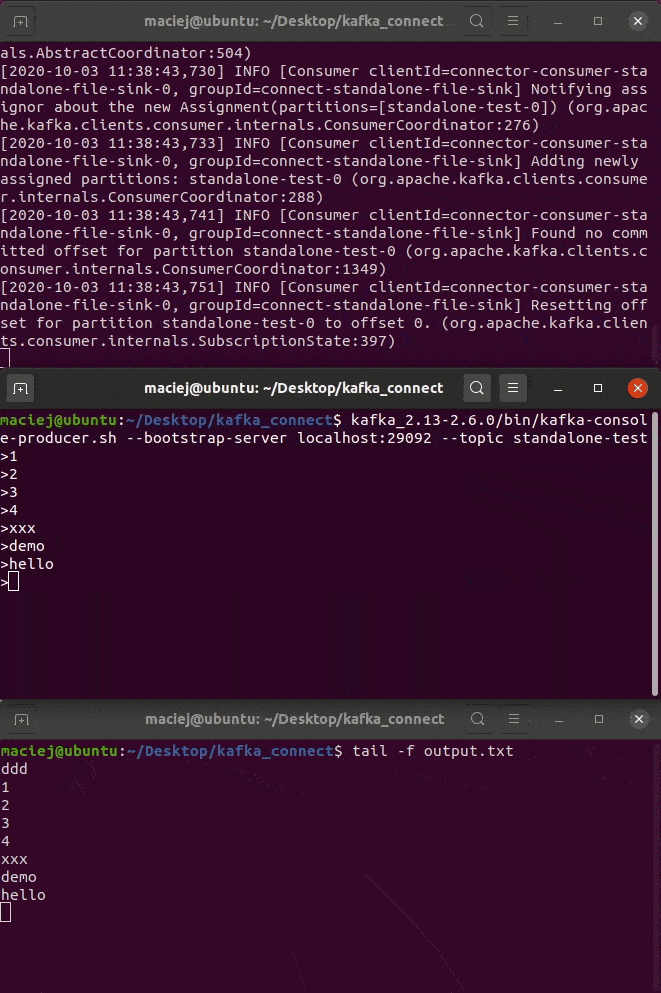
Tryb Distributed
To właśnie ten tryb zapewnia skalowalność i odporność na awarie. Wystarczy odpalić wiele workerów z tym samym group.id, a orchiestracja zadaniami zapewniona jest przez samą platformę. W przykładzie z generowaniem danych zobaczysz jak zachowa się Kafka Connect gdy ubijemy jednego z workerów. Poniżej plik konfiguracyjny jednego z workerów.
bootstrap.servers=localhost:29092 group.id=connect-cluster key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=false value.converter.schemas.enable=false offset.storage.topic=connect-offsets offset.storage.replication.factor=1 config.storage.topic=connect-configs config.storage.replication.factor=1 status.storage.topic=connect-status status.storage.replication.factor=1 #rest.host.name= rest.port=8083 plugin.path=/tmp/plugins/
- group.id = działa podobnie jak consumer group. Jeśli chcemy, by workery pracowały w klastrze, group.id muszą byc identyczne
- Kafka Connect trzyma dane w… Kafce. Trzeba wskazać nazwy topiców i oczekiwany replication factor.
- Do katalogu podanego plugin.path wrzucamy konektory. Wszystkie workery powinny mieć dostęp do tych samych konektorów.
Pozostaje odpalić worker Kafka Connect
kafka_2.13-2.6.0/bin/connect-distributed.sh connect-distributed-1.properties
Generowanie danych – Datagen Source
Wykorzystamy Kafka Connect Datagen. Jest to konektor do generowania danych. Może przydać się do jakiegoś PoC. Wystarczy go ściągnąć i rozpakowany katalog umieścić do katalogu podanym w plugin.path.
Zadania w Kafka Connect uruchamiamy za pomocą REST API. Najpierw trzeba przygotować konfigurację konektora.
{
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"kafka.topic": "distributed-test",
"quickstart": "ratings",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"max.interval": 100,
"tasks.max": "1"
}
Aby potem wysłać go pod scieżkę …/connectors/nazwa/config.
curl -X PUT -H 'Content-Type:application/json' http://localhost:8083/connectors/source-datagen/config -d @connect-datagen-source.json
Ale możemy skorzystać też z innych narzędzi, np. z wspomnianego wcześniej Conduktora.
Poniżej możesz zobaczyć GIF w którym odpalam konektor Datagen, a następnie stawiam i ubijam workery Kafka Connect.
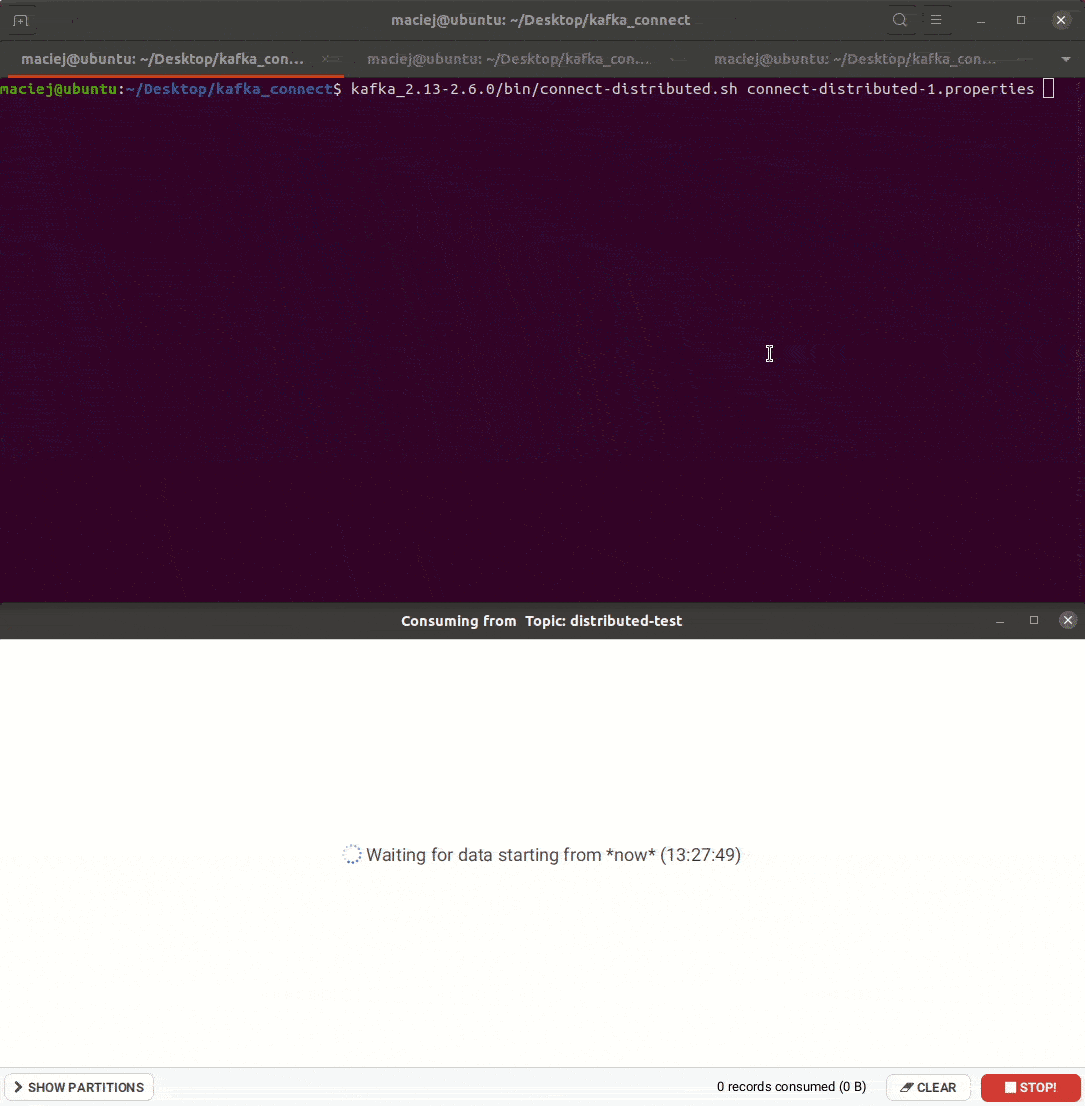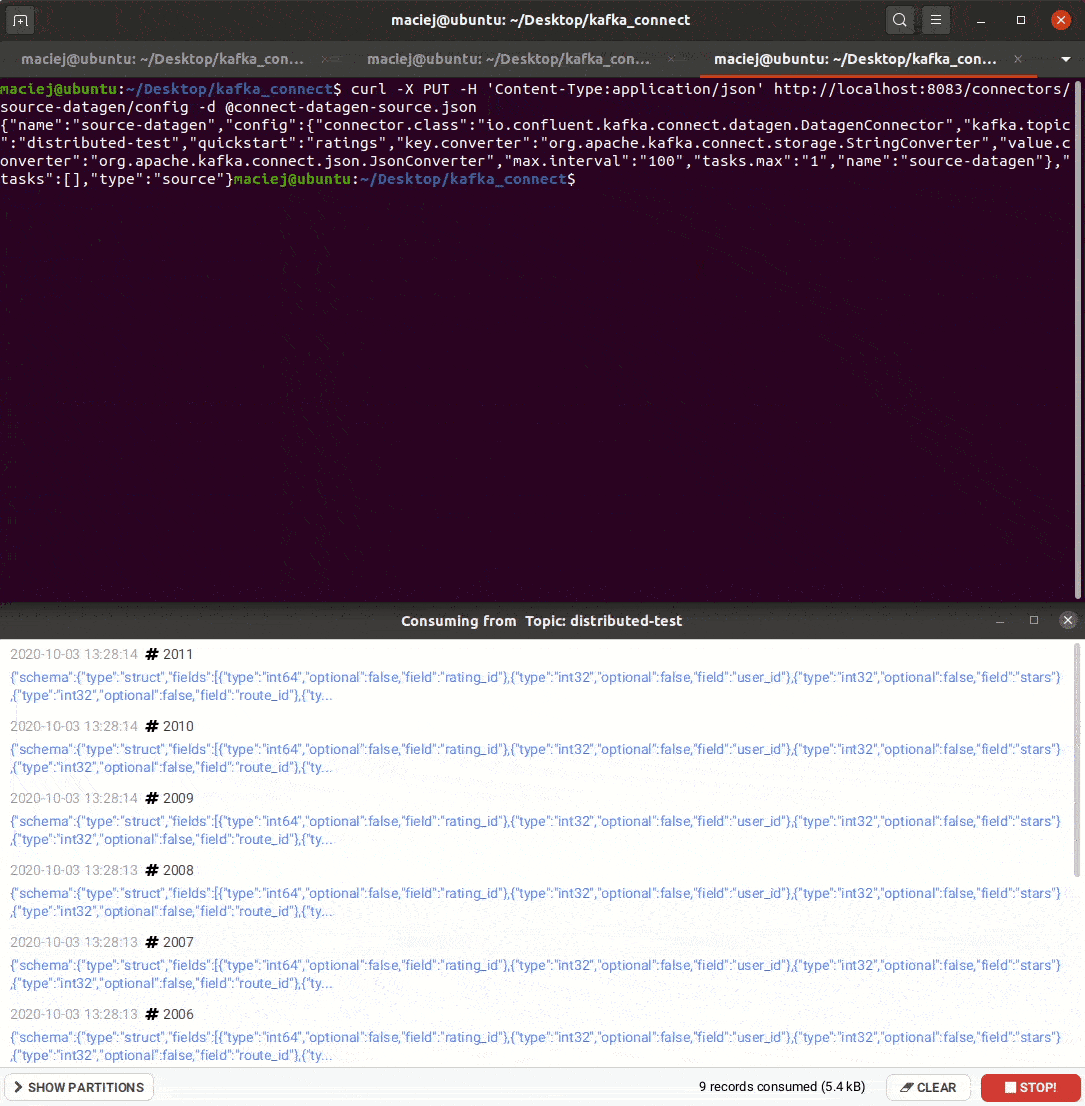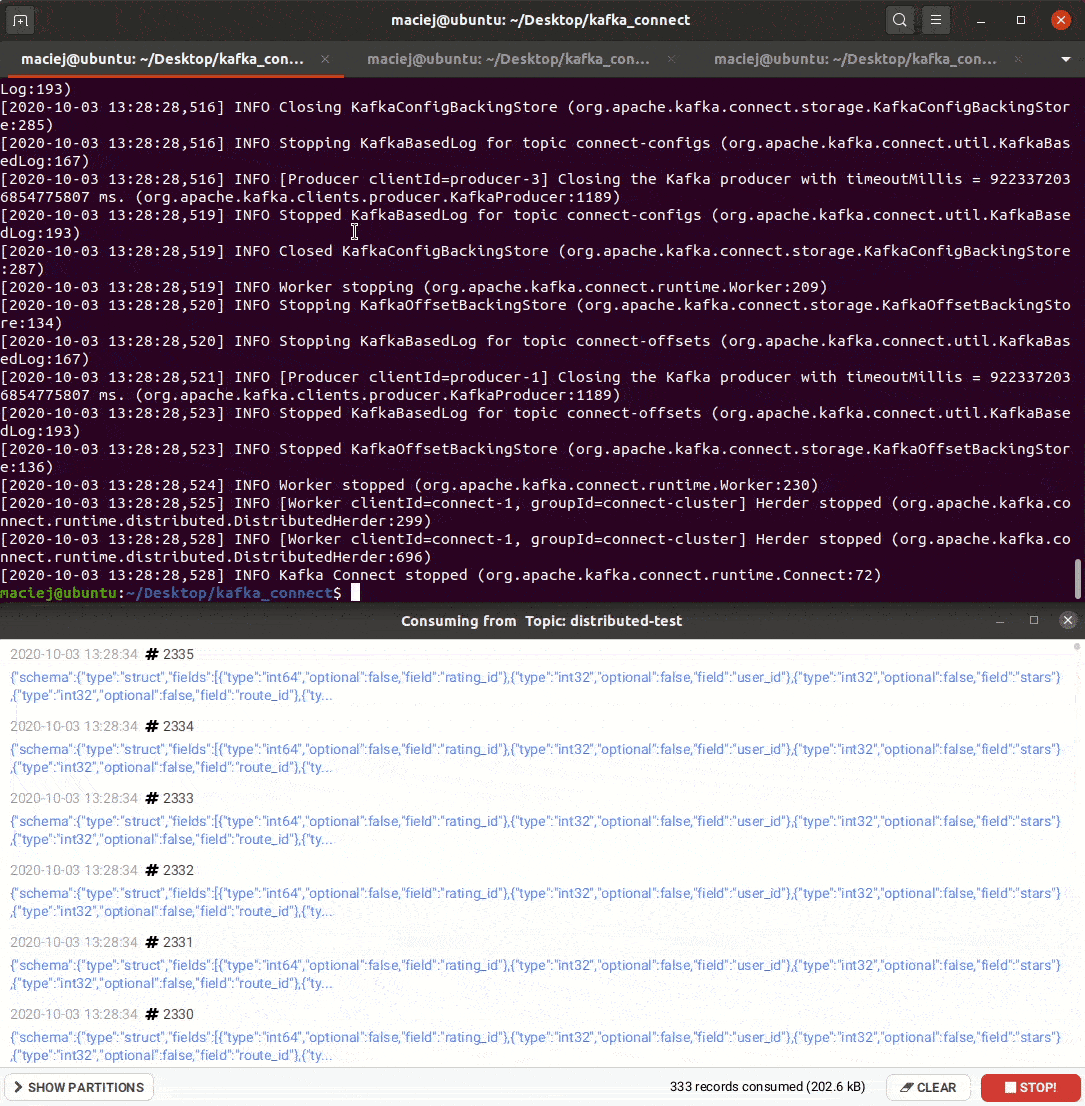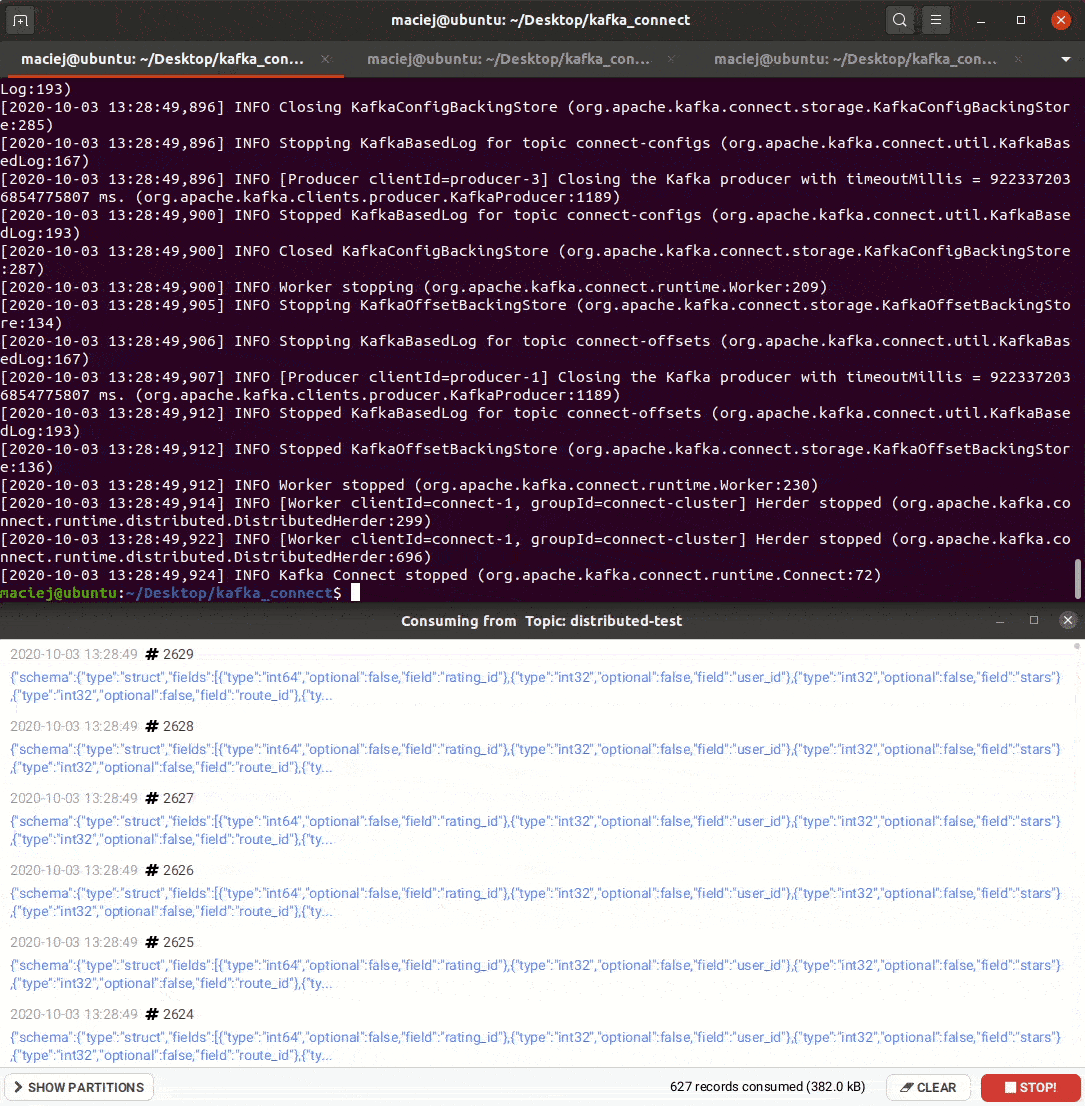
Zapis danych – AWS S3 Sink
Dane są generowane, przejdźmy do kwestii zapisu. Pierwotnie chciałem tu wykorzystać Elasticsearch Sink, ale nie mogłem obejść problemu z brakiem guavy w bibliotekach Kafki, a chciałem wypuścić ten artykuł w miarę szybko. Konektor AWS S3 znajdziesz tutaj. Kroki takie same jak w przypadku Datagen.
{
"name":"sink-minio",
"connector.class":"io.confluent.connect.s3.S3SinkConnector",
"tasks.max":"1",
"topics":"distributed-test",
"s3.bucket.name":"test",
"s3.part.size":"5242880",
"s3.compression.type":"gzip",
"flush.size":"100",
"aws.secret.access.key": "minio-secret-key",
"aws.access.key.id": "minio-access-key",
"store.url":"http://localhost:9000",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"format.class": "io.confluent.connect.s3.format.json.JsonFormat",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"schema.compatibility": "NONE",
"schemas.enable":false
}
- store.url wskazuje na lokalny kontener z MinIO
- flush.size – tyle rekordów będzie zawierać jedna paczka
- s3.compression.type – każda paczka będzie kompresowana (lub nie)
- value.converter – rekordy mogą być w róznych formatach. Tutaj akurat korzystamy z JSON.
curl -X PUT -H 'Content-Type:application/json' http://localhost:8083/connectors/sink-minio/config -d @connect-minio-sink.json

Zadanie z MinIO zostało dodane. Możemy sprawdzić czy faktycznie dane trafiają do kubełka.
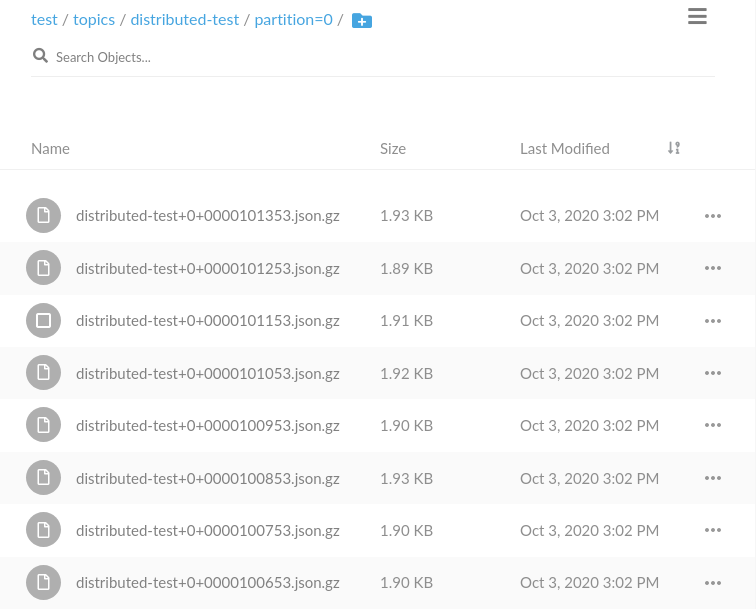
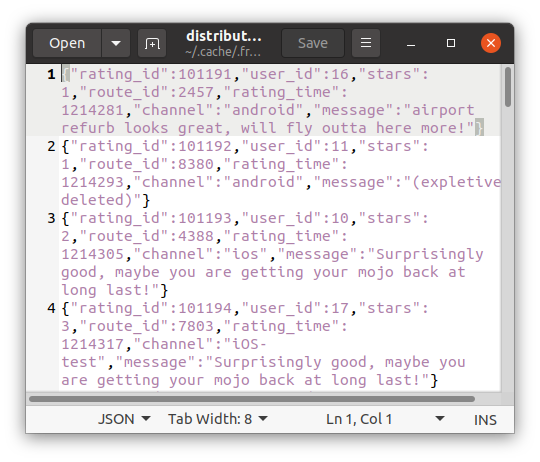
Podsumowanie
Jeśli dane mają iść prosto do/z Kafki, pokusiłbym się o Kafka Connect. W przypadku bardziej zaawansowanych operacji raczej widzę rozwiązanie w klimatach przetwarzania strumieniowego takie jak Logstash lub Spark Structured Streaming.
Repozytorium
https://github.com/zorteran/wiadro-danych-kafka-connect-nutshell

2 komentarze do “Kafka Connect w pigułce”