

Dane z Twitter można pozyskać na wiele sposobów, ale komu chce się pisać kod 😉. Szczególnie taki, który będzie działał 24/7. W Elastic Stack można w prosty sposób zbierać i analizować dane z Twitter’a. Logstash ma gotowe wejście do zbierania strumienia tweet’ów. Kafka Connect omawiana w poprzednim artykule również ma taką opcję, jednak Logstash może wysyłać dane do wielu źródeł (w tym do Apache Kafka) i jest prostszy w obsłudze.
W artykule:
- Zapis strumienia tweetów do Elasticsearch w Logstash’u
- Wizualizacje w Kibana (Xbox vs PlayStation)
- Usunięcie tagów HTML dla keyword’a mechanizmem normalizacji
Środowisko Elastic Stack
Wszystkie potrzebne komponenty znajdują się w jednym docker-compose. Jeśli masz już klaster Elasticsearch, wystarczy Ci Logstash.
version: '3.3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.9.2
restart: unless-stopped
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata:/usr/share/elasticsearch/data
restart: unless-stopped
ports:
- 9200:9200
kibana:
image: docker.elastic.co/kibana/kibana:7.9.2
restart: unless-stopped
depends_on:
- elasticsearch
ports:
- 5601:5601
logstash:
image: docker.elastic.co/logstash/logstash:7.9.2
volumes:
- "./pipeline:/usr/share/logstash/pipeline"
environment:
LS_JAVA_OPTS: "-Xmx256m -Xms256m"
depends_on:
- elasticsearch
restart: unless-stopped
volumes:
esdata:
driver: local
Logstash Pipeline
input {
twitter {
consumer_key => "loremipsum"
consumer_secret => "loremipsum"
oauth_token => "loremipsum-loremipsum"
oauth_token_secret => "loremipsum"
keywords => ["XboxSeriesX", "PS5"]
full_tweet => false
codec => "json"
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "tweets"
}
}
Aby uzyskać tokeny i klucze potrzebujesz deweloperskiego konta i aplikacji na Twitter. Tutaj załatwisz “formalności”.
Konfiguracja pipeline’a jest bardzo prosta. Strumień tweetów dotyczyć będzie słów podanych w keywords. Jeśli chcemy mieć więcej metadanych, wystarczy zmienić wartość full_tweet na true.
Dane
Wystarczy komenda docker-compose up -d i po chwili dane pojawiają się w indeksie tweets. W momencie tworzenia tego wpisu miałem już +- dwa dni zbierania danych. Indeks waży ~430 mb, czyli niezbyt wiele. Może inna licencja pozwoliła by na większy strumień danych. Wizualizacje w tym artykule obejmują dane z dwóch dni.
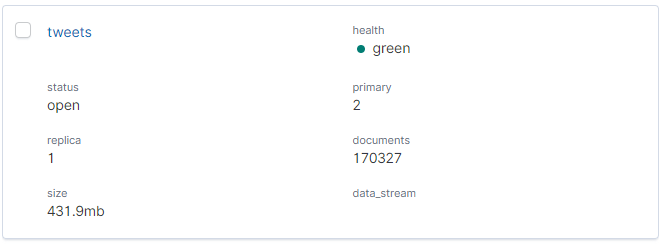
Index tweets już jest. Trzeba dodać Index Pattern, aby mieć możliwość korzystania z danych w Kibanie.
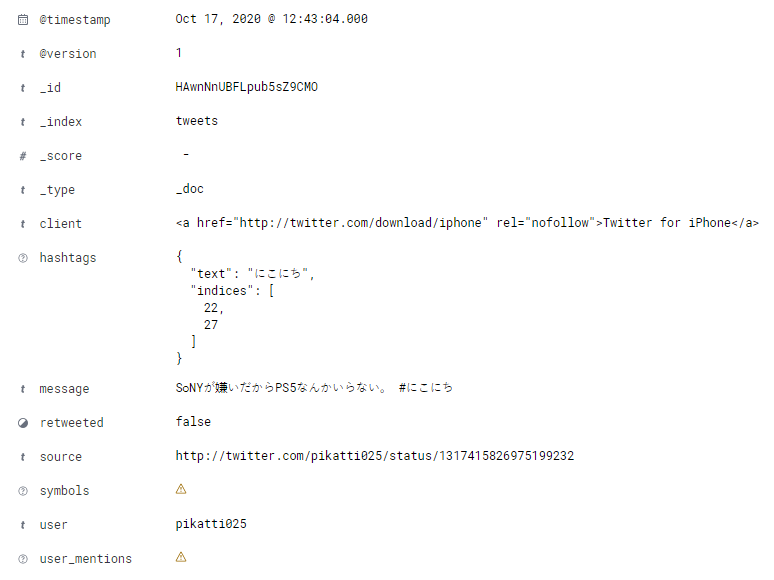
tweetsKibana
Tag Cloud – Xbox vs PlayStation
Na pierwszy rzut prosty Tag Cloud z agregacją po hashtags.text.keyword. PS5 wydaje się przeważać, ale upewnimy się korzystając z innych wizualizacji

Line – Xbox vs PlayStation

W tym przypadku również odnoszę wrażenie, że PlayStation góruje nad Xbox. Aby mieć 100% pewność, spróbujmy pogrupować hashtagi. Niektórzy używają PS5, inni ps5, a chodzi o ten sam produkt.
Jednak zanim przejdziemy dalej, pewna ciekawostka. Czy kolejność “kubełków” ma znaczenie? Oczywiście. Oto co się stanie jak zamienię histogram z Terms.
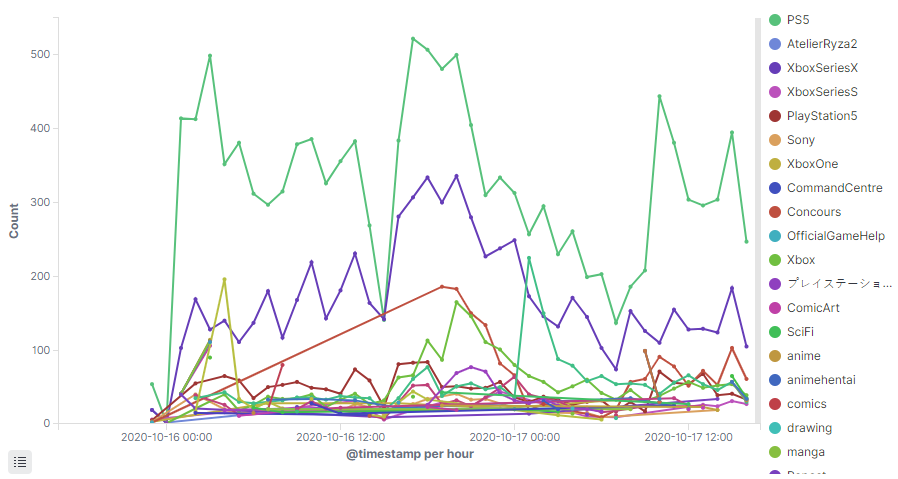
Otrzymaliśmy 10 hashtagów per interwał czasowy, zamiast 10 hasztagów dla całości
Do pogrupowania hashtagów możemy użyć agregacji Filters. Dodamy kilka bardziej licznych hashtagów, celowo pomijając drobnice. Składnia w polu Filter to KQL, czyli Lucene na sterydach.
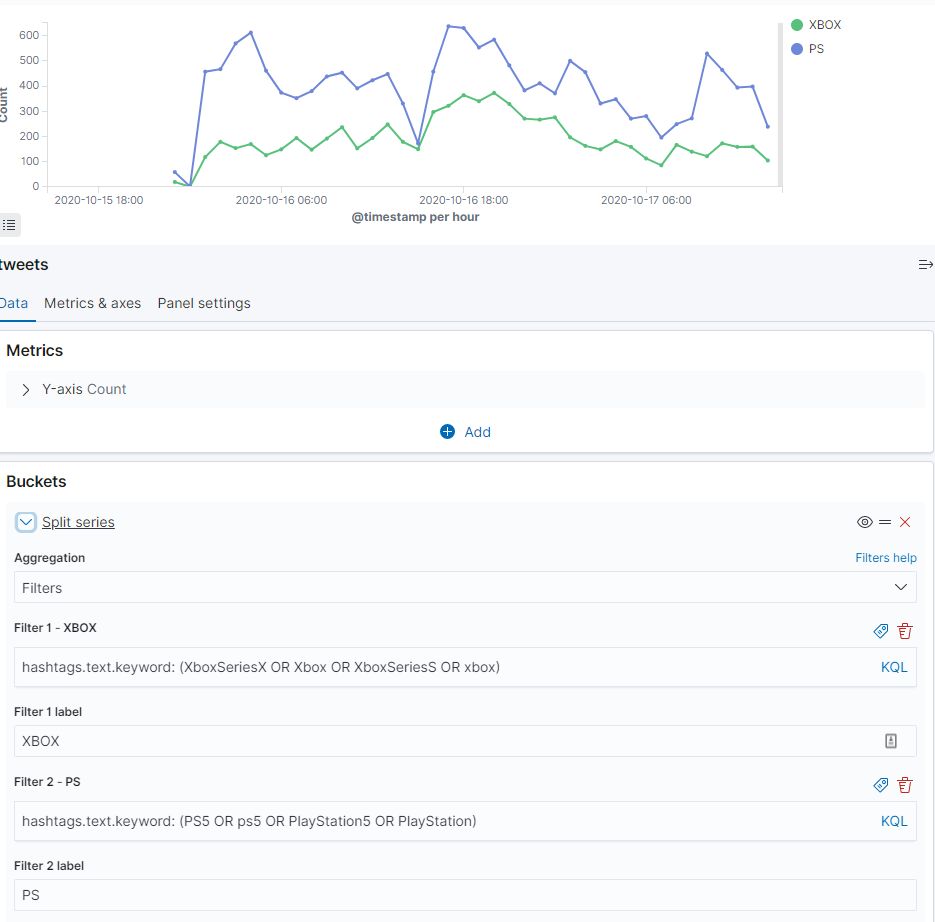
hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation) oraz hashtags.text.keyword: (XboxSeriesX OR Xbox OR XboxSeriesS OR xbox)
Teraz jestesmy pewni, że PlayStation ma większy rozgłos na platformie Twitter.
Timelion
Xbox vs PlayStation
To samo, a nawet więcej, możemy uzyskać w Timelion. Jest to ciekawe narzędzie do wizualizacji szeregów czasowych. Różni się od poprzedniego między innymi tym, że może wizualizować w jednym miejscu dane z wielu źródeł.
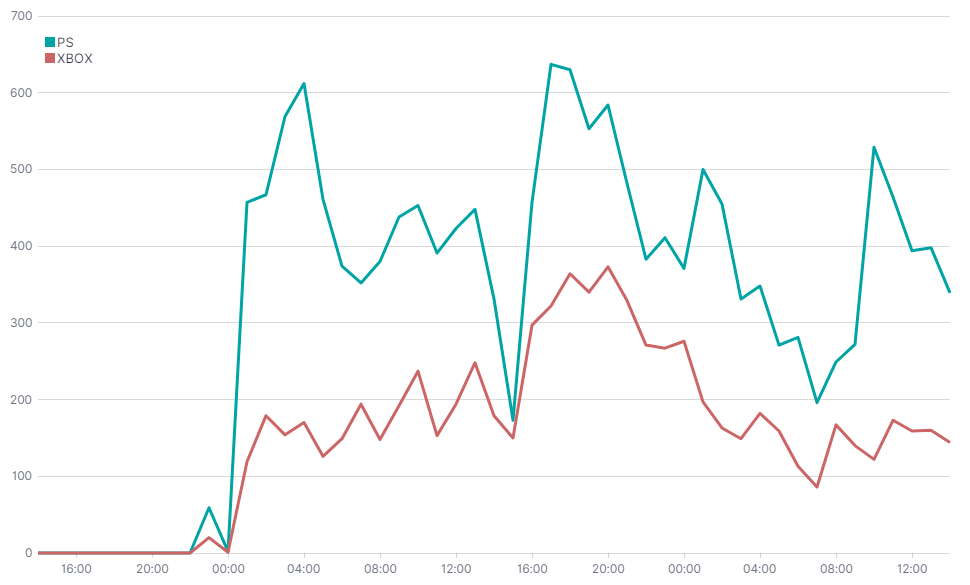
Do składni trzeba się przyzwyczaić. Poniżej kod który wygenerował powyższy wykres.
.es(index=tweets, q='hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation)').label("PS"),
.es(index=tweets, q='hashtags.text.keyword: (XboxSeriesX OR Xbox OR XboxSeriesS OR xbox)').label("XBOX")
Offset
Timelion oferuje możliwość przesuwania funkcji za pomocą parametru offset. Poniżej przykład zestawienia ilości tweetów o PlayStation z dniem poprzednim. Mało danych, więc efekt nie jest specjalnie porywający.
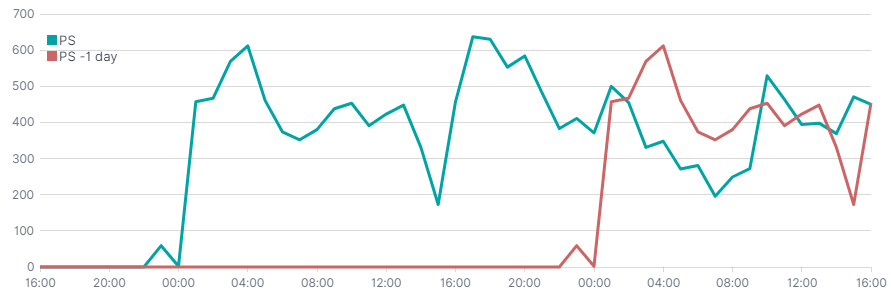
.es(index=tweets, q='hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation)').label("PS"),
.es(index=tweets, q='hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation)', offset=-1d).label("PS -1 day")
Zmiennośc funkcji / delta
Wykorzystując powyższy parametr oraz metodę subtract możemy wyliczać zmienność funkcji.

.es(index=tweets, q='hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation)')
.subtract(
.es(index=tweets, q='hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation)', offset=-1h)
)
.label("PS 1h delta"),
.es(index=tweets, q='hashtags.text.keyword: (XboxSeriesX OR Xbox OR XboxSeriesS OR xbox)')
.subtract(
.es(index=tweets, q='hashtags.text.keyword: (XboxSeriesX OR Xbox OR XboxSeriesS OR xbox)', offset=-1h)
)
.label("XBOX 1h delta")
Pie Chart – Typy klientów
Brzydkie ciastko
Przejdźmy do klientów używanych do pisania tweetów. Okazuje się, że sprawa jest trochę utrudniona. Pole client zawiera znacznik HTML który zmniejsza czytelność wykresu.
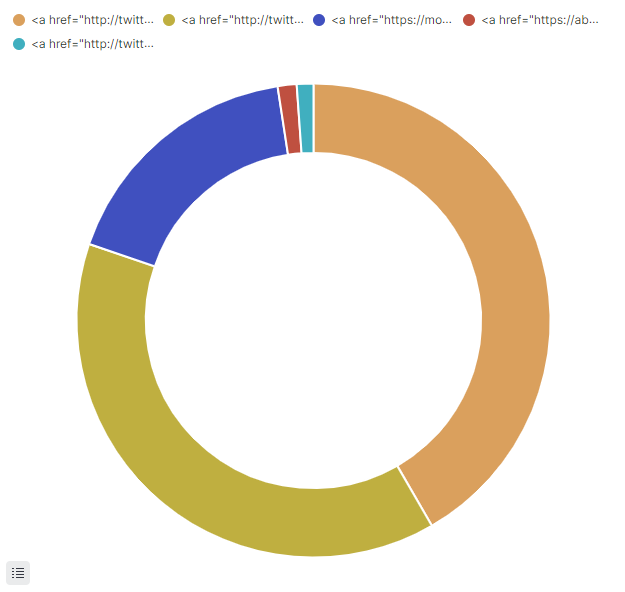
Ładne ciastko
Elasticsearch posiada spore możliwości przetwarzania tekstu. Filtr html_strip pozwala na usuwanie znaczników HTML. Niestety wykorzystanie go nic nam nie da, ponieważ analizatory można stosować tylko do pól typu text, natomiast nam zależy na polu keyword. Na tego typu polach można używać agregacji.

W przypadku pól keyword możemy użyć normalizatorów. Działają podobnie do analizatorów, ale na ich wyjściu otrzymujemy pojedynczy token.
Poniżej kod dodający normalizator do indeksu tweets. Nie mogłem wykorzystac html_strip, więc posłużyłem się wyrażeniem regularnym. Zmiana ustawień analizatorów w indeksie wymaga zamknięcia indeksu. Poniższe fragmentu kodu można użyć w Dev Tools w Kibanie.
POST tweets/_close
PUT tweets/_settings
{
"analysis": {
"char_filter": {
"client_extractor": {
"type": "pattern_replace",
"pattern": "<a[^>]+>([^<]+)</a>",
"replacement": "$1"
}
},
"normalizer": {
"client_extractor_normalizer": {
"type": "custom",
"char_filter": [
"client_extractor"
]
}
}
}
}
POST tweets/_open
Po dodaniu normalizatora, możemy zaktualizować właściwość client o nowe pole value.
PUT tweets/_mapping
{
"properties": {
"client": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
},
"value":{
"type":"keyword",
"normalizer":"client_extractor_normalizer"
}
}
}
}
}
Niestety to nie wszystko. Dane indeksują się w momencie ich dodawania do indeksu (dlaczego nie mogli nazwać tego kolekcją tak jak w MongoDB? 😅). Przeindeksowanie dokumentów możemy wymusić mechanizmem Update By Query.
POST tweets/_update_by_query?wait_for_completion=false&conflicts=proceed
Operacja zwróci id zadania i może chwilę potrwać jeśli masz sporo danych. Zadanie znajdziesz wpisując GET _cat/tasks?v

Po odświeżeniu Index Pattern w Kibanie, możemy podziwiać bardziej czytelny wykres. Podobna liczba użytkowników korzysta z iPhone i Android. Zaciekawił mnie klient Bot Xbox Series X

Co dalej?
Chciałem zbadać temat Spark NLP, ale stwierdziłem, że najpierw zbuduję strumień danych z Twitter. Planuję użyć gotowych modeli Spark NLP do wykrywania języka, sentymentu i innych parametrów, a to wszystko wykorzystując Spark Structured Streaming.
Repozytorium
https://github.com/zorteran/wiadro-danych-twitter-elastic-stack

Dzięki za opis!
Może podpowiesz jak filtrować na wejściu do elastica tweety po hashtagach? bo w tej chwili wpada masa treści nie związanych z interesującym mnie tagiem a jest to po prostu z tym wyrazem w tresci tweeta. Np interesuje mnie tylko hashtag #ADA
Możesz w sekcji `filter` w logstashu usuwać rekordy które nie mają tego hashtag’a. Służy do tego filtr drop (https://www.elastic.co/guide/en/logstash/current/plugins-filters-drop.html). IF’ologia w stylu “ADA” in [hashtags] powinna wystarczyć.