

Do tej pory operacje na zbiorze maili i haseł zaspokajały naszą ciekawość. Teraz wytworzymy wartość biznesową wykorzystując partycjonowanie danych. Na pewno wolelibyśmy uniknąć sytuacji w której ktoś korzystający z naszego systemu używa hasła które wyciekło.
Jest to jeden z artykułów dotyczących tego zbioru danych:
- Oczyszczenie i wykonanie prostych agregacji
- Porównanie formatów ORC, Parquet, JSON, CSV
- Osobiste haveibeenpwned – partycjonowanie danych (tutaj jesteś)
Surowizna
Sprawdźmy jak szybko uzyskamy odpowiedź działając na uzyskanych poprzednio danych w formacie Parquet. Graliście kiedyś w Commandos? Jeden z cheat-ów do tej gry (nie pamiętam co robił) to gonzo1982. Okazuje się że występuje w zbiorze, a zapytanie które tego dowiodło trwało aż 2:42 minuty.
breach.filter("password = 'gonzo1982'").show()
Distinct
Skoro interesują nas tylko hasła, powinniśmy wyczyścić zbiór z maili i duplikatów haseł. Wykorzystamy po prostu select i distinct. Przykłady kodów będą wykorzystywały PySpark-a.
from pyspark.sql import *
spark = SparkSession.builder.appName('breach_to_multiple_files').getOrCreate()
breach = spark.read.parquet("/data/breach_parquet/breach.parquet")
breach = breach.select("password").distinct()
breach.write.parquet("/data/breach_parquet_distinct")
Okazuje się że z ponad miliarda haseł unikalnych jest łącznie 453 018 810, natomiast rozmiar danych skurczył się do 4,5 GB w formacie Parquet z kompresją Snappy. Zapytanie tym razem trwało 21 sekund. Jest to prawie 8 krotna różnica. Czy można lepiej?
Distinct + partitionBy
Zapisując dane możemy skorzystać z metody partitionBy. Polega ona na podziale danych wyjściowych według podanych kolumn. Tworzone są oddzielne foldery dla każdej wartości z danej kolumny. Problem w tym, że w naszym DataFrame mamy tylko jedną kolumnę… Rozwiązanie? Utworzenie nowej kolumny gdzie wyodrębnimy pierwszą literę hasła. Jeśli hasło zaczyna się na g, tak jak w przypadku gonzo1982, zapytanie ograniczy się do jednego folderu.
from pyspark.sql import *
spark = SparkSession.builder.appName('breach_distinct_partition').getOrCreate()
breach = spark.read.parquet("/data/breach_parquet/breach.parquet")
breach = breach.select("password").distinct().withColumn("first_symbol",breach.password.substr(0,1))
breach.write.partitionBy("first_symbol").parquet("/data/breach_parquet_distinct_partitioned")
Dane ważą 4,3 GB, a zapytanie trwało 4 sekundy. Ponad 40 razy szybciej niż pierwotnie ?
breach_distinct_partitioned.filter("first_symbol = 'g' AND password = 'gonzo1982'").show()
UWAGA! Myśl o bezpieczeństwie
Oczywiście nie powinniśmy trzymać i porównywać haseł w postaci jawnej. Na stronie https://haveibeenpwned.com/Passwords dostępne są do pobrania hasła zhashowane funkcją skrótu SHA-1. Niestety pozostawia wiele do życzenia. warto rozważyć inną opcję. Tak czy inaczej, w sparku możemy zrobić to w taki sposób:
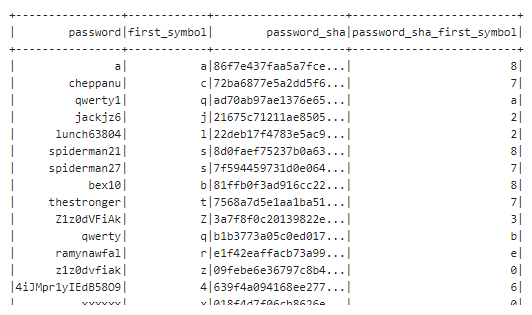
from pyspark.sql import functions as F
(breach
.select("password")
.distinct()
.withColumn("first_symbol",breach.password.substr(0,1))
.withColumn("password_sha", F.sha1(breach.password))
.withColumn("password_sha_first_symbol",F.col("password_sha").substr(0,1))
.show())
Wnioski
Warto zastanowić się nad użyciem partitionBy jeśli dane na to pozwalają.
