

Środowiska IT robią się coraz większe, rozproszone i ciężkie do zarządzania. Wszystkie komponenty systemu trzeba zabezpieczyć i monitorować przed cyber zagrożeniami. Potrzebna jest skalowalna platforma, która potrafi magazynować i analizować logi, metryki oraz zdarzenia. Rozwiązania SIEM potrafią kosztować niemałe pieniądze. W tym wpisie przyjrzymy się darmowemu rozwiązaniu dostępnego w Elastic Stack, czyli Elastic SIEM.
Część 2 znajdziesz tutaj
Z czego skorzystamy?
Elastic Stack jest to zbiór komponentów: Elasticsearch, Kibana, Logstash, Beats. Krótkie info o tym co jest użyte w tym wpisie:
- Elasticsearch – baza dokumentowa/silnik wyszukiwarki
- Kibana – “webowe GUI do” Elasticsearch
- Filebeat – lekki kolektor logów (dostępne moduły)
- Packetbeat – lekki kolektor protokołów sieciowych (i nie tylko)
- Audibeat – lekki kolektor zdarzeń security bez używania auditd
- Winlogbeat – lekki kolektor zdarzeń z systemów Windows.
Środowisko
Utworzyłem 3 maszyny wirtualne na chmurze Azure:
- ELK – Ubuntu 20.04 – Elasticsearch + Kibana
- Ubuntu1 – Ubuntu 20-04 – Filebeat, Packetbeat, Auditbeat
- Win10 – Windows 10 – Auditbeat, Packetbeat, Winlogbeat
Instalacja Elasticsearch + Kibana
Postawimy tu prosty klaster z jednym węzłem. Deb dla Elasticsearch znajedziesz tutaj, a dla Kibany tutaj.
Instalacja:
sudo dpkg -i nazwa_pliku.deb
Konfiguracja elasticsearch znajduje się w /etc/elasticsearch/elasticsearch.yml. To co warto zmienić to:
network.host: 0.0.0.0 # lub ip/host maszyny, by ES był widoczny z zewnątrz
discovery.type: single-node # bez tego ES będzie płakać przy 1-nodowym klastrze i network.host który nie jest localhostem
Konfiguracja elasticsearch znajduje się w /etc/elasticsearch/elasticsearch.yml. To co warto zmienić to:
W przypadku kibany ( /etc/kibana/kibana/yml ) zmień:
server.host: "0.0.0.0"
Teraz można odpalić serwisy.
sudo systemctl enable elasticsearch
sudo systemctl enable kibana
sudo systemctl start elasticsearch
sudo systemctl start kibana
Jeśli wszystko jest ok, powinieneś móć użyć curl-a i dostać odpowiedź od ES.
root@ELK:/home/azureuser# curl localhost:9200
{
"name" : "ELK",
"cluster_name" : "siem",
"cluster_uuid" : "u6FDeHNsTmWJcnf-jYUH7Q",
"version" : {
"number" : "7.8.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "b5ca9c58fb664ca8bf9e4057fc229b3396bf3a89",
"build_date" : "2020-07-21T16:40:44.668009Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Kibana natomiast jest pod portem 5601 dostępnym z przeglądarki.

Dodanie logów z Ubuntu
Instalacja i konfiguracja Beatsów jest prosta.
Filebeat -> syslog
Deb z Filebeatem ściągniesz tutaj. Po instalacji (dpkg -i nazwa_pakietu.deb) w pliku /etc/filebeat/filebeat.yml:
filebeat.config.modules.reload.enabled: true # aby nie restartować co chwile serwisu
setup.kibana.host: “10.0.0.4:5601” # wskazanie na kibane w cleach konfiguracji
output.elasticsearch.hosts: [“10.0.0.4:9200”] # wskazanie na węzły elasticsearch
monitoring.enabled: true # chcemy mieć metryki beats-a w kibanie
Gdy już to zrobimy, należy skonfigurować Elasticsearch pod Filebeata. Filebeat skonfiguruje ILM, template, dashboardy i temu podobne. Służy do tego komenda:
filebeat setup
Załózmy, że chcemy zbierać syslog z maszyny. Do wyświetlenia dostępnych modułów i włączenia sysloga należy:
filebeat modules list
filebeat modules enable system
Konfiguracja modułu system znajduje się w pliku /etc/filebeat/modules.d/system.yml. Jeśli nie zmieniałeś domyślnych ścieżek, wystarczy zostawić enabled: true.
# Module: system
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.8/filebeat-module-system.html
- module: system
# Syslog
syslog:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths:
# Authorization logs
auth:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths:
Teraz wystarczy włączyć filebeat:
sudo systemctl enable filebeat
sudo systemctl start filebeat
Auditbeat
Sprawa wygląda podobnie jak z Filebeat. Deb znajdziesz tutaj. Jedyna różnica to ścieżka pliku konfiguracjnego (/etc/autidbeat/auditbeat.yml).
Ten beats nie ma modułów. Wszystkie możliwości znajdziesz w tym jednym pliku yml. Pamiętaj, aby użyć “auditbeat setup” i włączć serwis.
Packetbeat
Sodobnie jak z Filebeat. Deb znajdziesz tutaj. Jedyna różnica to ścieżka pliku konfiguracjnego (/etc/packetbeat/packetbeat.yml).
Ten beats nie ma modułów. Wszystkie możliwości znajdziesz w tym jednym pliku yml. Pamiętaj, aby użyć “packetbeat setup” i włączyć serwis.
Dodanie logów z Windows 10
Winlogbeat
Plik instalacyjny znajdziesz tutaj. Ja użyłem wersji MSI 64x.
Pliki konfiguracyjne znajdziesz w C:\ProgramData\Elastic\Beats\winlogbeat. Zmienić trzeba to, co w przypadku Ubuntu, czyli głównie adresy kibany i elasticsearch.
Konfiguracja polega na odpaleniu komendy w Powershellu:
winlogbeat.cmd setup
Natomiast serwis włączamy tak:
Start-Service winlogbeat
Moduł SIEM w Kibana
Moduł SIEM jest dostępny gdy w indeksach (filebeat-*, packetbeat-*, auditbeat-*) znajdą się dane zgodne z ECS. ECS jest to ustalony przez Elastic mapping indeksów. Jeśli myślałeś, że Elasticsearch, lub w ogóle bazy NoSQL, nie posiadają schematu, to nie jest prawda ?.
Jeśli potrzebujesz logów z aplikacji/systemu, który nie jest dostępny jako moduł w jednym z beats-ów, musisz te logi dostarczyć i przetworzyć właśnie w mapping zgodne z ECS. Możesz do tego użyć Filebeat i Logstash.
Moduł SIEM znajduje się po lewej stronie
W zakładce overview, już widać efekty zbieranych logów z jednej maszyny.

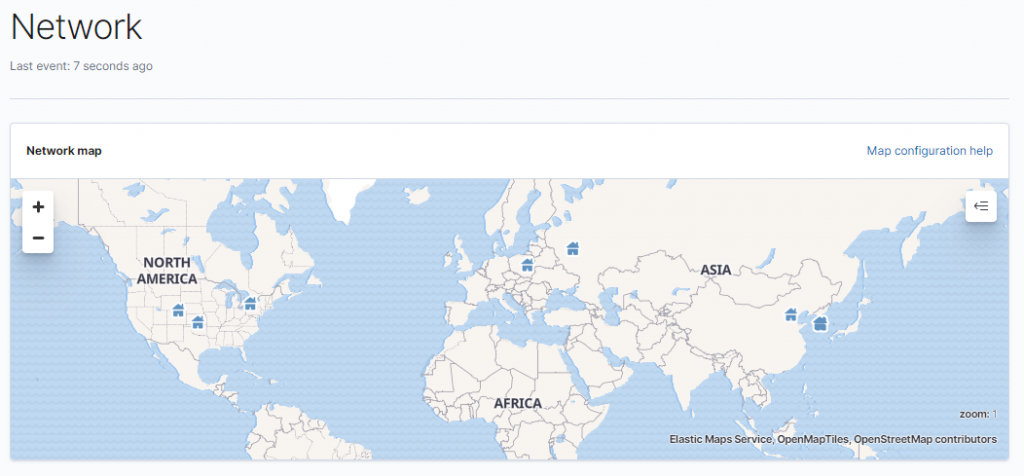
W zakładce Network, oprócz danych Source IPs i Destination IPs, mamy widoczną mapkę z geolokalizacjami adresów:
Instalacja beatsów i rozejrzenie się po Kibanie trochę zajęło. I wiesz co? W tym samym czasie już było 20 prób zalogowania się po SSH do maszyny.

Widzimy ilość prób, użytkownika, adresy IP.

Timeline
Przeprowadźmy dochodzenie!
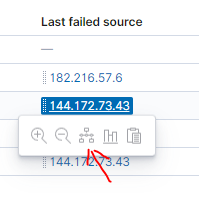
Timeline to narzędzie do zawężania widoku. W ten sposób mozemy dodawać nowe filtry i uzyskać bardziej szczegółowy widok sytuacji. Poniżej widać zarówno rekordy związane z netflow (packetbeat), jak i błędy logowania (auditbeat) dotyczące danego IP. Jak widać atakujący wychodził z różnych portów.
Efekty możemy zapisać, a spostrzeżenia dodawać jako notatki do przypadku.

Filtrowanie
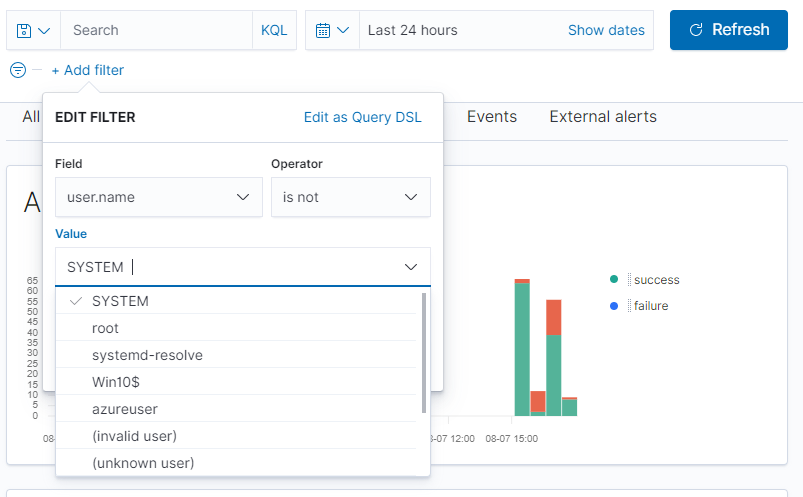
Nie zawsze należy ślepo wierzyć w dashboard. Dwie maszyny, a aż 113 zalogowań? Na pewno ktoś przejął maszynę ?.
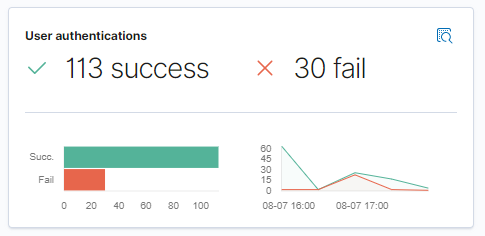
Użytkownik SYSTEM (i nie tylko) zakłamuje sytuację. Wyrzućmy go z widoku za pomocą filtra.

Kurs Elastic Stack
Jestem w trakcie tworzenia kursu z Elastic Stack. Przejdziesz tam drogę od postawienia klastra, wypełnienia go danymi, zabezpieczenia, administracji i wyszukiwania. Wszystko to oparte o darmową licencję. W przyszłości planuję również rozszerzenie go o moduł związany z cyberbezpieczeństwem. Jeśli jesteś zainteresowany, tutaj jest link.
W następnym odcinku
Temat SIEM został tylko lekko dotknięty. W następnym wpisie z tej serii dowiesz się jak zabezpieczyć klaster. Jak widać, włam na klaster Elasticsearch to nie jest nic nadzwyczajnego. Odblokujemy tym samym zakładkę Detections.

Czesc,
Zacząłem przygodę z ELK na Debian10, instalacja ok logi z lokalnej maszyny pięknie się czytają. Problem jest kiedy z pomocą filebeat chce zaciągać auditd. Logi owszem idą ale na dashboardzie przygotowanym z ELK dla auditd nie ma połowy danych jak np event.action, user.name. Poki co nie che korzystać z auditbeat. Jak masz radę z chęcią przyjmę. Docelowo chce to zintegrować z suricata.
Poradziłem sobie. Mam nadzieje ze bardziej rozudowany kurs będzie dostępny za darmo wi poruszysz w nim dużo ciekawych zagadnien jak np logstash widze ze go nie używasz.
Super, że się udało. Na razie nie planuje darmowej wersji kursu, ale może wpadnie coś na na bloga lub YouYube. Aktualnie domykanie tematów w ramach kursu zabiera mi sporo czasu.