
W poprzednim wpisie udokumentowałem utworzenie przepływu danych wykorzystującego technologie takie jak Kafka, Kafka Streams, Logstash i Elasticsearch. Po kilku dniach pracy mam już wystarczającą ilość danych, aby przekonać się jakie możliwości analizy danych transportu miejskiego umożliwia Elasticsearch i Kibana.
Dane
Pierwszy rekord trafił 2020-06-02 20:24:58 (wtorek). Screenshot poniżej wykonałem w niedzielę wieczorem, czyli około 4,5 gb na 5 dni. API jest pytane co 10 sekund

W momencie gdy piszę ten artykuł pod aliasem ztm znajduej się 16578668 rekordów
GET ztm/_count
Liczność zbioru
Wykorzystując agregację cardinality, możemy sprawdzić jak liczny jest zbiór linii i pojazdów. Wychodzi na to, że jest około 309 linii autobusowych i 1828 pojazdów.
Pewnie dziwisz się, czemu napisałem “około”. Odpowiedź jest w dokumentacji. Zapytanie to (jak wiele innych w Elasticsearch) zwraca tylko szacunkowe wartości. Wyjaśnię to kiedyś na blogu.
POST ztm/_search
{
"size": 0,
"aggs": {
"cardinality_lines": {
"cardinality": {
"field": "lines"
}
},"cardinality_vehicle": {
"cardinality": {
"field": "vehicleNumber"
}
}
}
}
Wynik:
{
"took" : 475,
"timed_out" : false,
"_shards" : {
"total" : 9,
"successful" : 9,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"cardinality_lines" : {
"value" : 309
},
"cardinality_vehicle" : {
"value" : 1828
}
}
}
Mapa
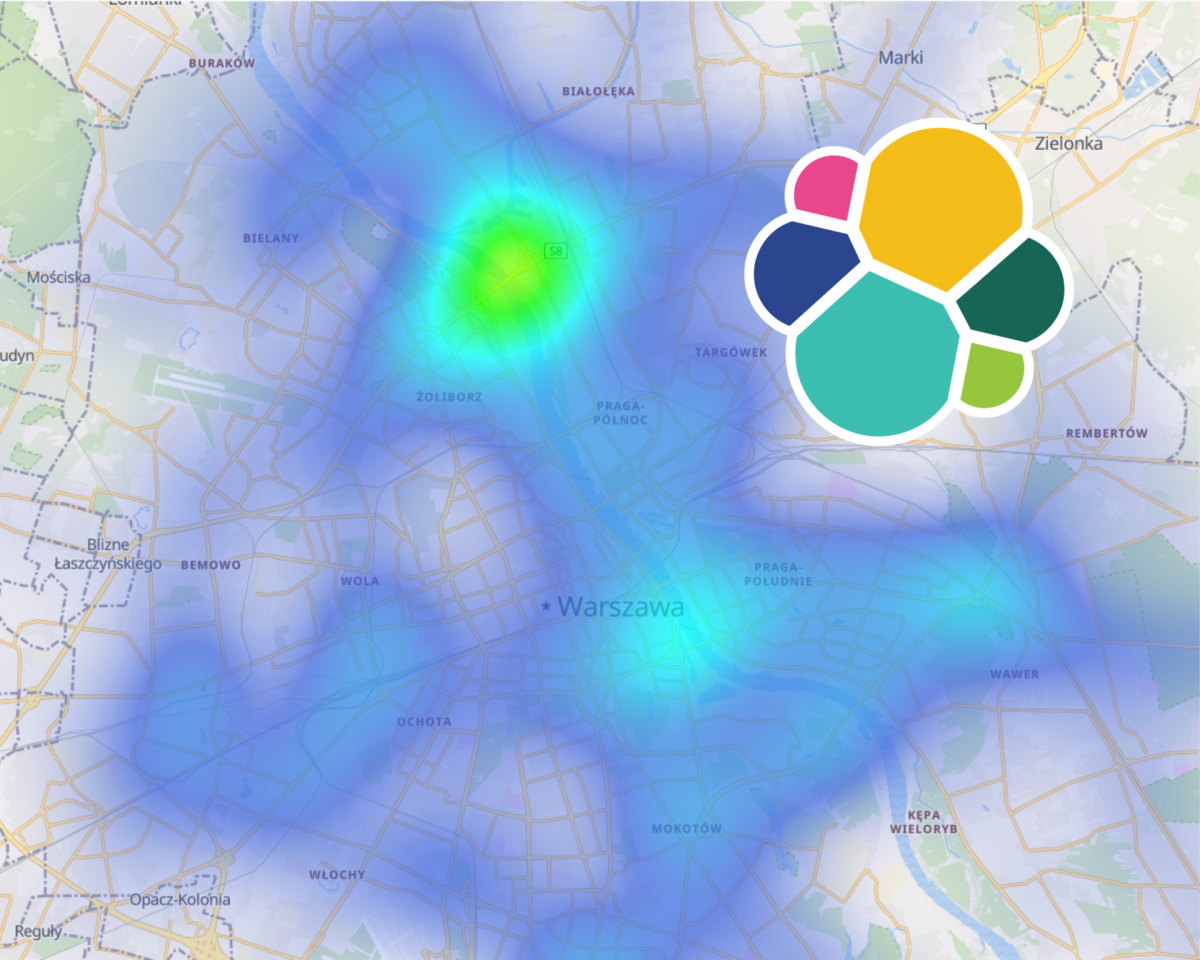
Oglądanie ruchu miejskiego na mapie pozwala na analizy wykorzystując interfejs białkowy (czyli nas ?). Poniżej widać zgromadzenia pojazdów sugerujące pętle autobusowe.
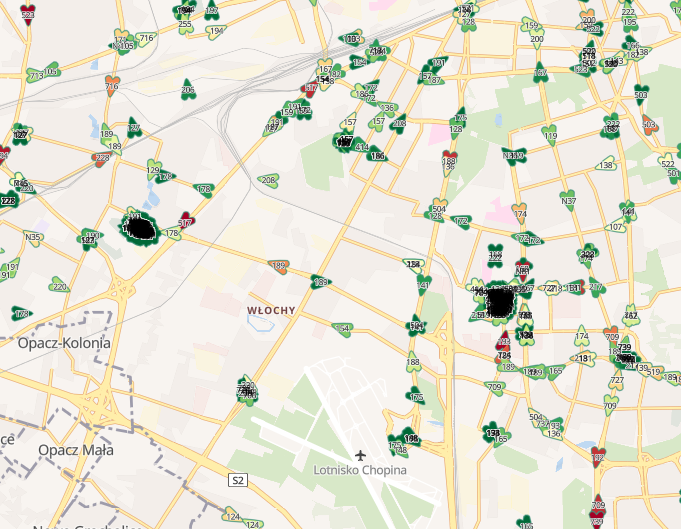
Jednak mapy w Kibana umożliwiają również dodawanie warstw związanych z agregacjami dokumentów.
Heatmap
Niestety heatmap-a nie pozwala na agregacje wykorzystującą średnią. Technicznie można to obejść, ale póki co sprawdźmy bez kombinowania, co możemy uzyskać wykorzystując proste zliczenia rekordów.
Do dyspozycji są filtry, sprawdźmy jak wygląda heatmap-a dla rekordów z prędkością większą niż 50 km/h.
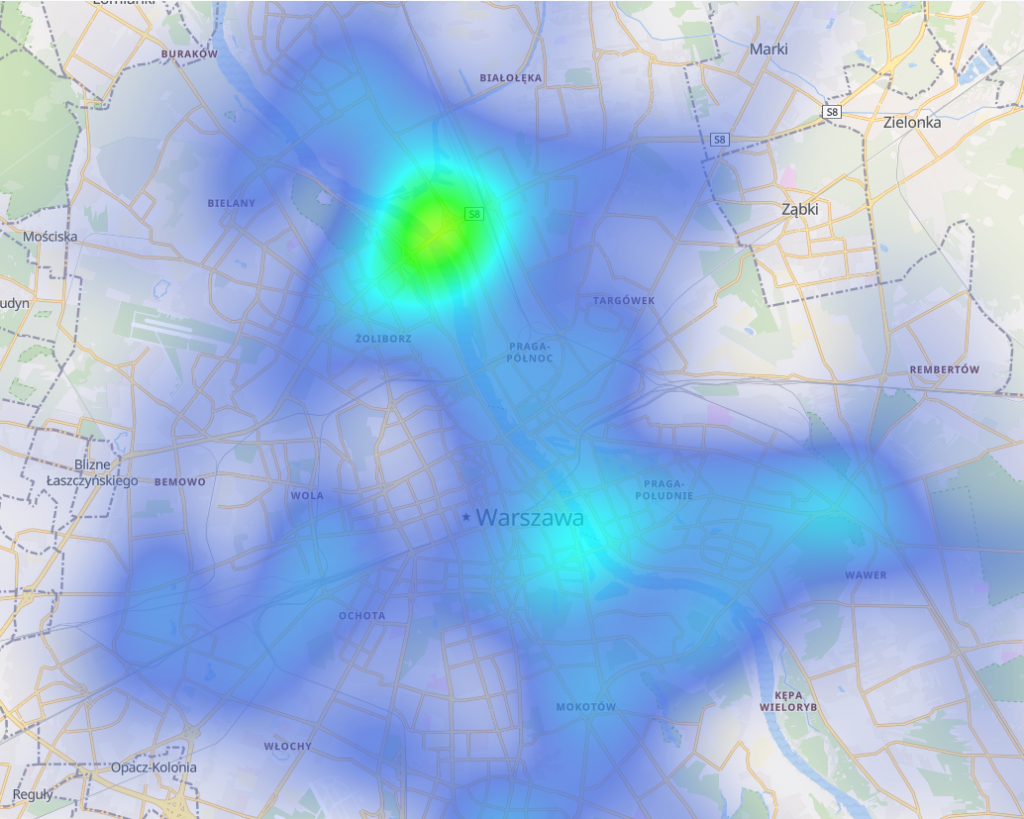
Wyróżniają się mosty oraz drogi powiązane z tranzytem. A jak zanegujemy ten warunek?

Teraz przeważa centrum oraz pętle autobusowe. Trzeba pamiętać, że to nie są średnie prędkości tylko zliczenia rekordów (stojący na pętli autobus może nadawać)
Grid rectangles
Kolejny typ agregacji na mapie to siatka. Tutaj już możemy zastosować średnią po prędkości. Zerknijmy na początek jak wygląda Warszawa z daleka oraz centrum i okolice
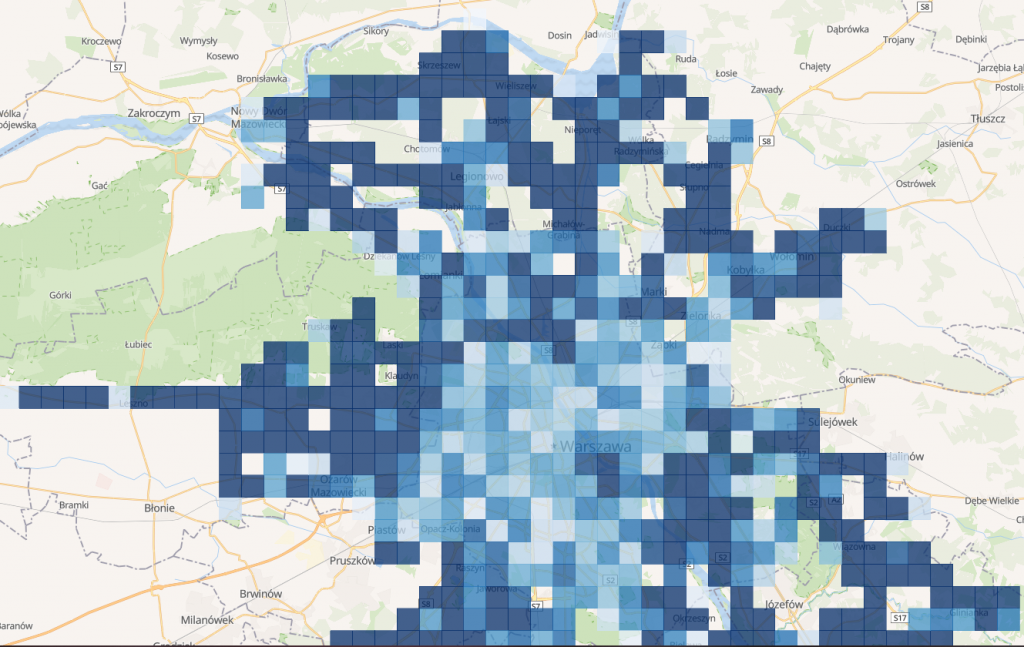
Wartości i rozmiar kwadratów zależny jest od tego, jaki obszar oglądamy i z jakim przybliżeniem

Im ciemniejszy odcień niebieskiego, tym prędkości są wyższe. Widać wyróżniającą się wisłostradę.
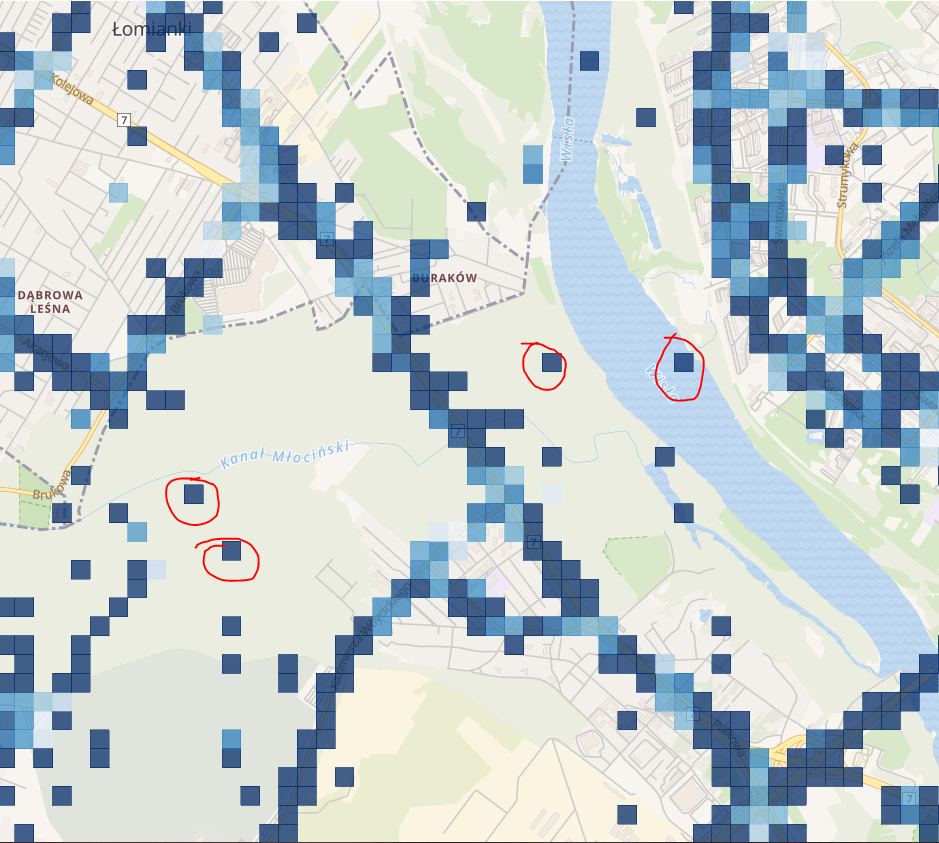
Powyżej natomiast dojazd do Warszawy z kierunki Łomianek. Pierwsza rzecz jaką widać to niedokładność pomiarów. Autobusy raczej nie zahaczają o Wisłę lub pobliskie lasy ?.
Po prawej na dole widać duże prędkości na moście północnym. Skupmy się jednak na fragmencie drogi koło lasu Młociny. Na pierwszy rzut oka nie jest tak źle. Co się stanie jak dodamy warunek który pokaże rekordy pojazdów kierujących się na południowy wschód?
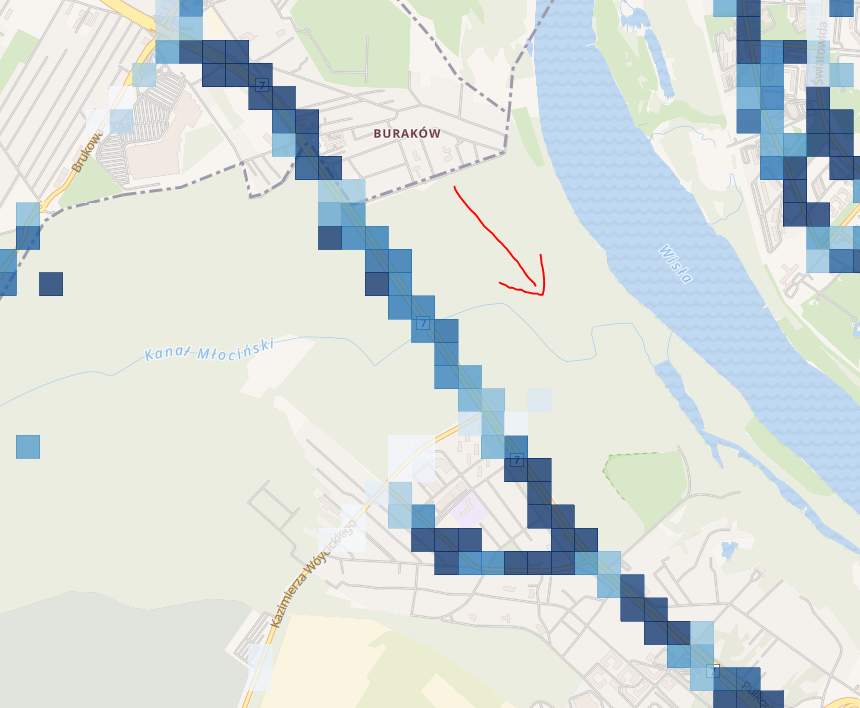
Prędkości znacznie spadły. Przecież codziennie rano setki kierowców stoją w tym miejscu w korku. Kierowcy autobusów nie są z tej “atrakcji” zwolnieni ? A co w przypadku kierunku północny zachód?
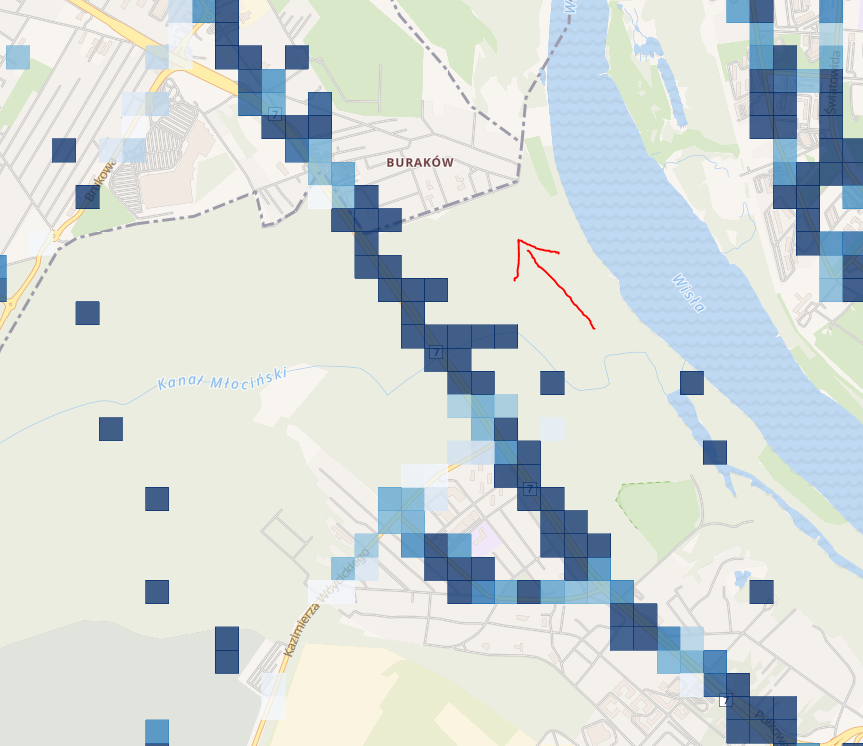
Tutaj jest już znacznie szybciej. Wróćmy jednak do kierunku południowy wschód i sprawdźmy, jak wygląda różnica między godziną 6:00-9:00, a 9:00-12:00.

Analizować mapy można długo i namiętnie. Wydaje mi się, że powyższe obserwacje udowodniły wartość jaka drzemie w mapach w Kibanie.
Wykresy, wykresiki
Mapy mapami, sprawdźmy, czy wyjdą jakieś sensowne wykresy ze zgromadzonych danych. Na pierwszy rzut idzie histogram po dacie. Agregacje tworzone są dla rekordów 03.06.2020 – 07.06.2020
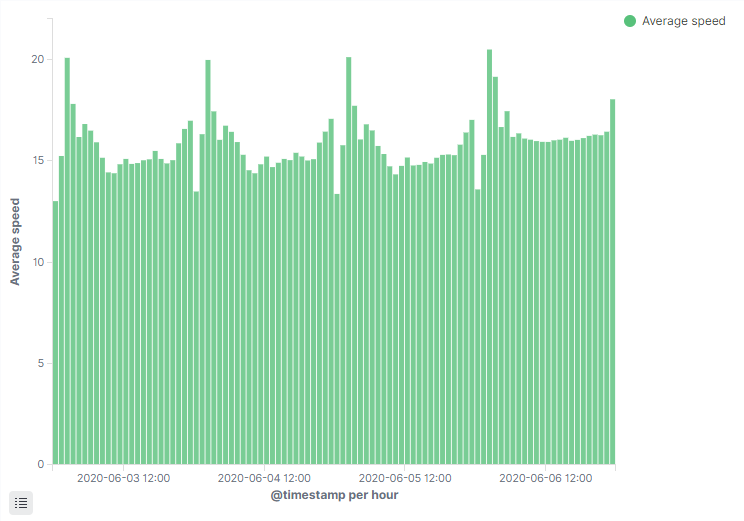
Powyższy wykres jest histogramem po dacie dla średniej prędkości. Jednak czegoś mi w nim brakuje. Dla kilkunastu/dziesięciu dni nie byłby już tak czytelny. Przydałby się wykres ala histogram zbiorczo dla każdej godziny w ciągu doby. Nie jest to jednak takie proste.
Dodanie pola z godziną
Pierwsze co przyszło mi do głowy to Scripted Fields w Kibana. Niestety pola takie są tylko do odczytu i nie można robić po nich agregacji (chyba, że o czymś nie wiem)
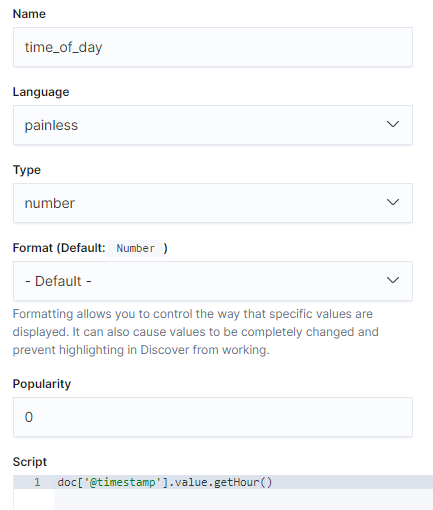
Script Fields w zapytaniu do Elasticsearch też nie da rady. Możemy coś wyświetlić, ale nie przeniesiemy tego do Kibany.
POST ztm/_search
{
"_source": "@timestamp",
"script_fields": {
"test1": {
"script": {
"lang": "painless",
"source": "doc['@timestamp'].value.getHour()"
}
}
}
}
W rezultacie musiałem użyć zapytania Update By Query, wykonując na każdym rekordzie skrypt dodający nowe pole z godziną na podstawie @timestamp. Danych było 4,5 gb, więc trochę się pomieliło ? docelowo przydałoby się zaktualizować utworzony wcześniej pipeline w Logstash.
Wykresiki – ogólnie
Osobiście oczekiwałem większego spadku w godzinach szczytu. Ciekawe, że 22 jest dość “wolna”.

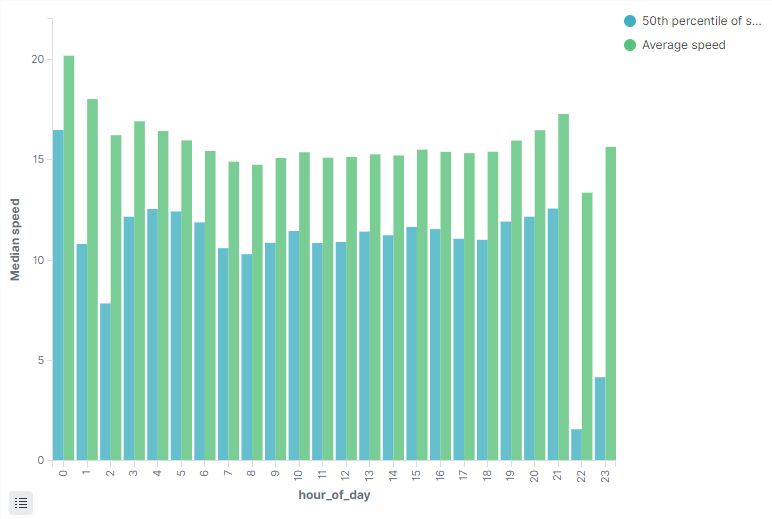
Mediana + średnia już daję trochę większy obraz tego, jak wygląda ruch. Może te niskie prędkości 22-23 są spowodowane autobusami, które stoją na pętli, ale nadają?
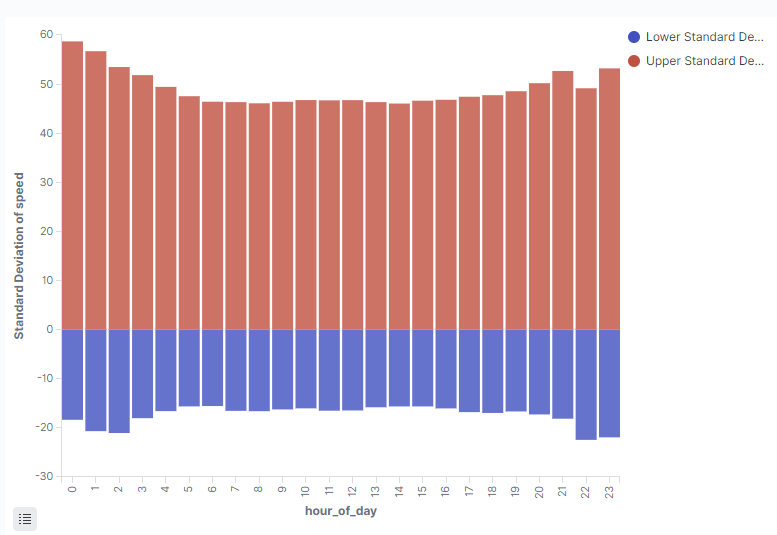
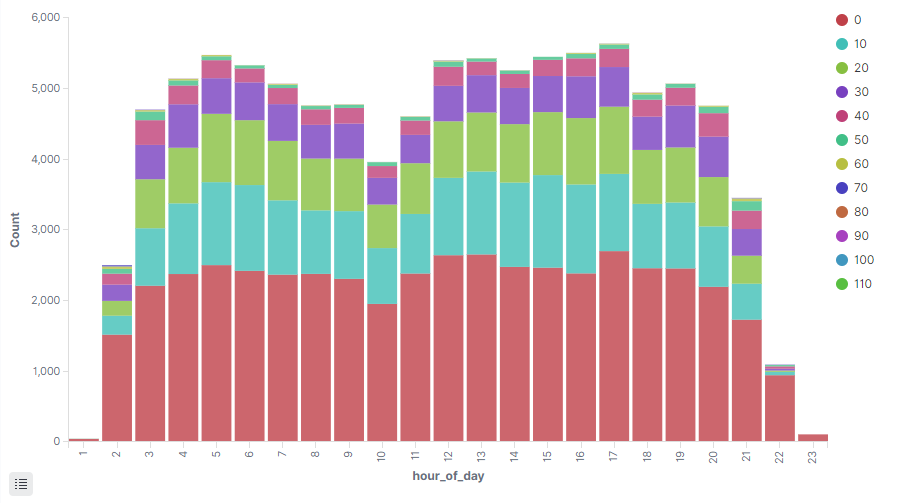
Próbowałem różnych kombinacji agregacji i ten poniżej wygląda ciekawie. Jest to histogram po godzinie doby, w którym jest histogram po prędkości z interwałem 10 km/h. Wysokość słupków to ilość rekordów, więc oprócz prędkości, widzimy również, jak dużo było czynnych autobusów.


Wykresiki – dla linii 122 i 190

Najszybszy w mieście wóz, najszybszy w mieście
Wiem, że czekaliście tylko i wyłącznie na to. Jaka linia jest najszybsza? Oto skrypt (kibana nie potrafiła posortować percentyli ?). 99 percentyl prędkości.
POST ztm/_search
{
"size": 0,
"aggs": {
"by_lines": {
"terms": {
"field": "lines",
"size": 10
},
"aggs": {
"95_percentile_speed": {
"percentiles": {
"field": "speed",
"percents": [
99
]
}
},
"sales_bucket_sort": {
"bucket_sort": {
"sort": [
{
"95_percentile_speed[99.0]": {
"order": "desc"
}
}
]
}
}
}
}
}
}
Wyniki:
{
"key" : "186",
"doc_count" : 225539,
"95_percentile_speed" : {
"values" : {
"99.0" : 65.91829377908059
}
}
},
{
"key" : "112",
"doc_count" : 171393,
"95_percentile_speed" : {
"values" : {
"99.0" : 64.00226838213632
}
}
},
{
"key" : "509",
"doc_count" : 186253,
"95_percentile_speed" : {
"values" : {
"99.0" : 62.05728980093291
}
}
},
{
"key" : "523",
"doc_count" : 176120,
"95_percentile_speed" : {
"values" : {
"99.0" : 59.11082142026221
}
}
},
{
"key" : "190",
"doc_count" : 179619,
"95_percentile_speed" : {
"values" : {
"99.0" : 58.488623481840385
}
}
},
{
"key" : "116",
"doc_count" : 190566,
"95_percentile_speed" : {
"values" : {
"99.0" : 54.07943470657681
}
}
},
{
"key" : "105",
"doc_count" : 179109,
"95_percentile_speed" : {
"values" : {
"99.0" : 53.821592225265405
}
}
},
{
"key" : "189",
"doc_count" : 266184,
"95_percentile_speed" : {
"values" : {
"99.0" : 53.12168077972748
}
}
},
{
"key" : "179",
"doc_count" : 207693,
"95_percentile_speed" : {
"values" : {
"99.0" : 49.59739096543882
}
}
},
{
"key" : "157",
"doc_count" : 171677,
"95_percentile_speed" : {
"values" : {
"99.0" : 46.13637487155884
}
}
}
Wnioski
Ciężko szukać tu zaskakujących wniosków dotyczących ruchu transportu publicznego. Bardziej coś w stylu “lepiej być pięknym, zdrowym i młodym, niż starym, chorym i brzydkim” 🙂 Brakuje też kontekstu analizy. Szukanie dla samego szukania nie jest raczej zbyt owocne.
W mojej ocenie Elasticsearch i Kibana daje sporo możliwości out-of-the-box. Cały proces od przetwarzania do analizy i wizualizacji mieści się w licencji Basic. Trzeba tylko pamiętać, że to nie spark i podobne, więc wszystkie operacje dostosowujące i denormalizujące dane powinny być wykonane przed wrzuceniem ich do Elasticsearch.
Dane, chociaż wstępnie czyszczone w Kafka Streams, nadal zostawiają wiele do życzenia. Od kwestii związanych z dokładnością i filtrowaniem bezsensownych rekordów, do znakowania konkretnych tras linii oraz ich kierunku. Takie wzbogacone dane umożliwiłyby kolejne analizy i wnioski.
Jeśli masz jakiś ciekawy pomysł, daj znać 🙂

Hej,
Agregacja po scripted fields jest mozliwa.
Sprobuj zmienic wartosc w polu Script dla time_of_day na:
doc[‘timestamp’].value.hourOfDay
Pozdrawiam!
Kasia, faktycznie! Działa 🙂 Dziękuję za info
Cześć, fajny blog, ciekawie przestawiony stos ELK ?
1.Masz może ciekawe pomysły co do monitorowania przyrotu wielkości indeksów?
2. Lub monitorowanie zapytań userów? Które są najczęściej, a które zajmują najwięcej czasu elastic owi (ten standardowy przykład z oficjalnego forum średnio się sprawdza)
Dzięki 🙂
– Jeśli nie wystarcza Ci standardowy monitoring dostępny w Kibana, pierwsze co przychodzi mi do głowy to jakiś skrypt, który co jakiś interwał pyta o szczegóły indeksów i wrzuca ich rozmiary na Elasticsearch. Zgaduję, że można coś podobnego zrobić w Grafanie, ale nie mam w tym doświadczenia
– Hmm, a jakby schować ES za jakimś reverse proxy (nginx/apache) i monitorować je w Elasticsearch? ?
1. Finalnie zacząłem odpytywać api o rozmiar każdego indexu i będę wysyłał to do grafany.
2. Mamy każdą kibanę schowaną za nginxem, ale w access logu loguje tylko
POST /nazwa_kibany/elasticsearch/_msearch?rest_total_hits_as_int=true&ignore_throttled=true HTTP/1.1″ 200, także szukam dalej bo jeszcze nie mogę przechwycić body requestu. Dziękuję za chęć pomocy 🙂
Można w nginx logować body z tego co widzę: https://gist.github.com/morhekil/1ff0e902ed4de2adcb7a , może tym tropem
Dziękuję za chęć pomocy, sprawdzę 😉
Hi, this is really very nice blog, your content is very interesting and engaging, worth reading it. I got to know a lot from your articles. Thanks for sharing your knowledge.I want to share about about confluent kafka training
Excellent post! This post was delivered a lot of information. Thanks for the effort to share this with us. Keep updating.
python Training in chennai
python Course in chennai