

Elasticsearch zaskakuje nas swoimi możliwościami i szybkością działania, ale czy zwracane wyniki są prawidłowe? W tym wpisie dowiesz się jak Elasticsearch działa pod maską i dlaczego zwracane agregacje są pewnego rodzaju przybliżeniem.
Elasticsearch pod maską
Indeksy, shardy i repliki
Zacznijmy od tego, jak Elasticsearch organizuje dane. Koncepcje indeksu na pewno już znasz, przypomina tabelę w relacyjnej bazie danych. Każdy indeks składa się z co najmniej jednej sharda i dowolnej ilości replik.
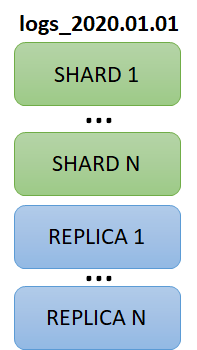
Shardy dzielą dane w indeksie. Taki shard można alokować na różnych węzłach w klastrze. Dzięki temu uzyskujemy rozproszenie. Uogólniając, na podstawie routingu, dodawany dokument trafi do sharda pierwszego, kolejny do drugiego itp.
Repliki natomiast pełnią rolę ochrony przed awarią oraz wspomagają odczyty (zapisywać można tylko do primary shardów, odczytywać można z shardów i ich replik). Załóżmy, że masz index o konfiguracji 3 primary shardy i 2 repliki. Ile łącznie (primary + replica) shardów będzie miał index? 9 (1, 1′, 1″, 2, 2′, 2″, 3, 3′, 3″) .
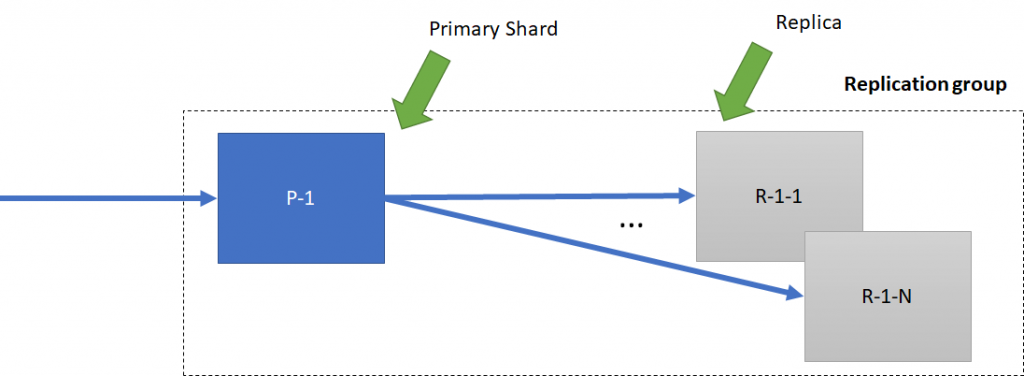
Primary shard i repliki w ramach tych samych danych tworzą replication group. Gdy nowy rekord trafia do primary shard, jest on odpowiedzialny za wysyłanie go do replik.
Zapytania i agregacje
Już wiemy jak mnie więcej to wygląda jeśli chodzi o alokacje. Teraz przejdźmy do zapytań.
Gdy prosimy o konkretny rekord, zapytanie przekazywane jest do węzła z shardem gdzie ten się znajduje. Węzeł wie co i gdzie to na podstawie metadanych (odpowiada za nie węzeł z rolą master).

Gdy pytamy o zbiór dokumentów lub agregację, zapytanie trafia do wszystkich węzłów zawierających shardy pytanego indeksu. Te zwracają wynik do węzła, który agreguje wyniki i zwraca je do klienta.

Szacowanie
Dlaczego zwracana agregacja jest szacowaniem? Przyjrzyjmy się Terms Aggregation, czyli po SQL-owemu taki GROUP BY + COUNT.
Załóżmy, że mamy 3 shardy, w każdym z nich są jakieś rekordy. Pytamy klaster o to, aby zliczył wszystkie powtarzające się wartości jakiegoś pola. Na podstawie poprzedniej sekcji wiemy, że takie zapytanie trafia do każdego z węzłów. Załózmy, że jest tak jak na obrazku poniżej.
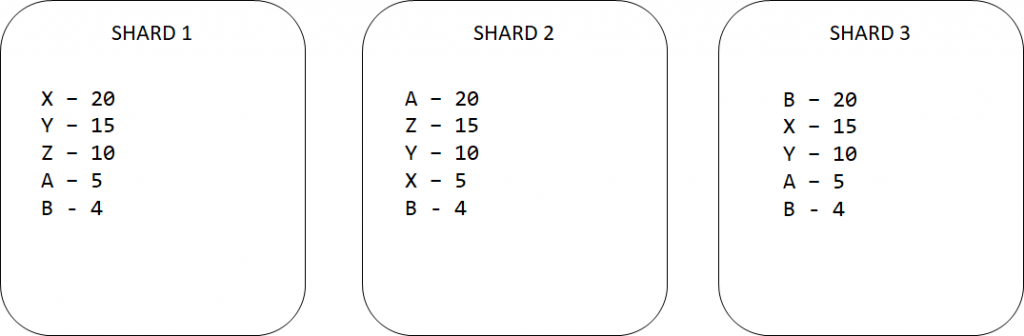
Zapomniałem wspomnieć, że chcieliśmy TOP 3 wartości. Czyli każdy węzeł bierze swoje TOP 3 i zwraca je do węzła, który koordynuje zapytanie.
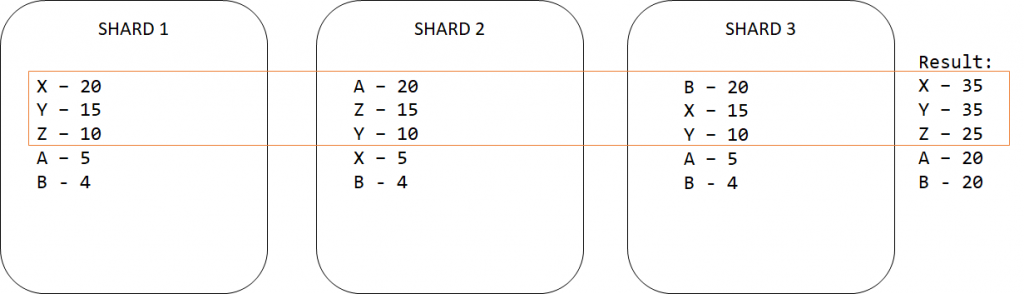
Po dłuższym zastanowieniu jednak chcemy TOP 4. Pytamy klaster o to samo i dostajemy inne wyniki. Nie dość, że X ma więcej rekordów, to A i Z zamieniły się miejscami.
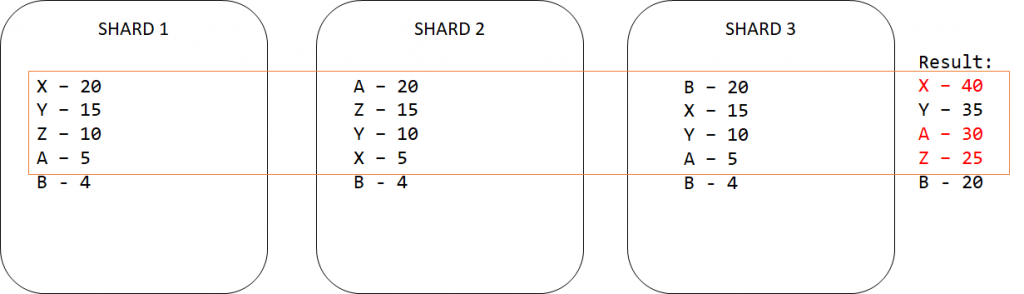
Test
W poprzednich wpisach opisywałem zbieranie, przetwarzanie i analizę danych autobusów w Warszawie. Sprawdźmy, czy na podstawie tego zbioru danych rekordy będą różne. Aby mieć porównanie, użyłem Apache Spark razem z biblioteką elasticsearch-spark. Jak chcesz ją podpiąć do Spark-a, zerknij do tego wpisu.
DataFrame w Apache Spark
W indeksie Elasticsearch, gdzie mam dane autobusów, pole daty nie ma standardowego formatu, więc musiałem opcję es.mapping.date.rich ustawić na false.
val es = spark.read.format("org.elasticsearch.spark.sql")
.option("es.nodes.wan.only","true")
.option("es.port","9200")
.option("es.net.ssl","false")
.option("es.nodes", "http://hadoop06")
.option("es.net.http.auth.user","elastic")
.option("es.net.http.auth.pass","xxxxxxx")
.option("es.mapping.date.rich","false")
val ztm = es.load("ztm")
Top 20 Lines
Wersja Apache Spark:
ztm.groupBy("lines").count().orderBy(desc("count")).show()
Wersja Elasticsearch
POST ztm/_search
{
"size": 0,
"aggs": {
"num_of_lines": {
"terms": {
"field": "lines",
"size": 20
}
}
}
}
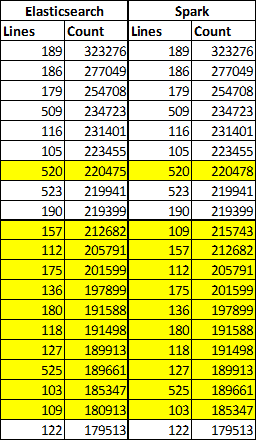
Różnic jest sporo, ale jest to spowodowane przesunięciem. Count w większości rekordów jest taki sam. A jak zrobimy rosnąco, zamiast malejąco?
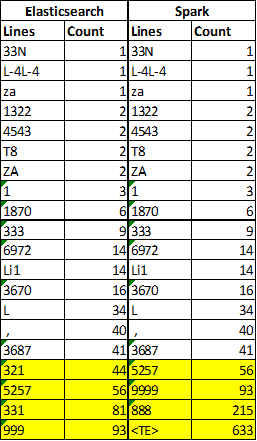
Przy okazji dowiedzieliśmy się jakie głupoty czasami dostajemy od API. Kolejny raz widać jak ważna jest jakość danych, a co za tym idzie, kontrola tej jakości.
Top 10 vehicleNumber
Wersja Apache Spark:
ztm.groupBy("vehicleNumber").count().orderBy(desc("count")).show()
Wersja Elasticsearch
POST ztm/_search
{
"size": 0,
"aggs": {
"num_of_vehicle_number": {
"terms": {
"field": "vehicleNumber"
}
}
}
}
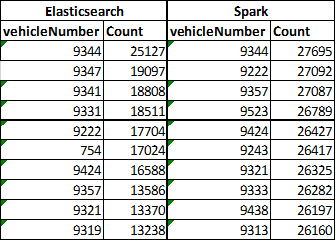
W tym przypadku mało co się zgadza. Jedynie rekord z pierwszego miejsca jako tako można zaliczyć.
Czy można coś z tym zrobić?
Im większy size w zapytaniu do Elasticsearch, tym bardziej zbliżone do poprawnych będą wyniki, ale będziemy musieli dłużej na nie czekać. Oprócz parametru size można użyć shard_size. Parametr ten definiuje ile rekordów ma zwrócić węzeł liczący do węzła koordynującego, a jego domyślna wartość to (size * 1.5 + 10). Jest też opcja wyświetlenia wartości błędu dla najgorszego przypadku parametrem show_term_doc_count_error (pomaga przy ustalaniu shard_size).
Wnioski
Jak widać, czasami Elasticsearch potrafi nas oszukać. Czy to źle? Wszystko zależy od naszych oczekiwań. Jest jeden parametr, o którym jeszcze nie wspomniałem. Czas wykonywania zapytań. Elasticsearch odpowiadał momentalnie. Na wynik Apache Spark musiałem trochę poczekać.
Jak to się mówi: życie to kwestia wyborów 🙂 albo szybko, albo dokładnie

Jeden komentarz do “Dlaczego Elasticsearch kłamie? Jak działa Elasticsearch?”