

Dziś przyjrzymy się narzędziu, jakim jest Apache Airflow. Spróbujemy użyć dwóch operatorów i zasilić kafkę danymi z API. Przy okazji rozpoczynam taki “mini projekcik”. Nie wiem jak Tobie, ale najlepiej poznaję różne technologie poprzez praktykę.
W tym wpisie wspomniałem o źródle, którym są otwarte dane Warszawy https://api.um.warszawa.pl/. Mój plan to wysyłanie takich danych na Kafkę i przetworzenie ich strumieniowo (np. w Sparku). Takie dane potem wylądują na HDFS, ELK (sprawdzimy czy da się sensownie je zwizualizować), może RethinkDB + aplikacja JS, może wizualizacja w PowerBI… jak masz jakiś pomysł/uwagi daj znać ?.

Skąd te dane?
Aby otrzymać lokalizacje GPS pojazdów komunikacji miejskiej należy założyć konto na w.w stronie oraz bić na poniższy URL:
https://api.um.warszawa.pl/api/action/busestrams_get/?apikey={tutaj wpisz swoj apikey}&type={1 dla autobusów, 2 dla tramwajów}&resource_id=f2e5503e927d-4ad3-9500-4ab9e55deb59

Apache Airflow
Co to jest? Jest to takie narzędzie do harmonogramowania wielu zadań. W chmurze GCP znane jest pod hasłem Cloud Composer. Workflow jest to tzw. DAG (Directed Acyclic Graph), czyli skierowany, acykliczny graf składający się z zadań. DAG-i pisze się w Pythonie, ale istnieje interfejs graficzny, wizualizacja, monitorowanie i wiele innych.
W tym przypadku użyję dwóch operatorów: HttpOperator, aby pobrać dane oraz PythonOperator, aby wysłać je na Kafkę. Zadanie docelowo ma odpalać się co 10 sekund.
Jak postawić?
Najprostszy sposób na postawienie Apache Airflow to użycie Dockera. Ja użyłem docker-compose z tego repozytorium: https://github.com/puckel/docker-airflow . Jeśli wykorzystujesz jakiś dodatkowy pakiet python w DAG-u, pamiętaj o pliku requirements.txt (szczegóły w opisie repo).
Konfiguracja
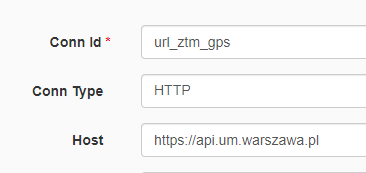
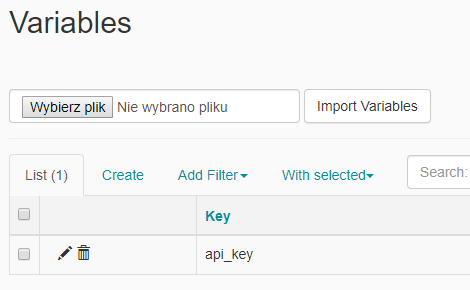
Do użycia HttpOperator potrzebujemy dodać odpowiedni Connection z adresem api. Aby nie trzymać apikey w kodzie dodamy również Variable. To wszystko wyklikamy w web apce.
Używamy Kafki, więc warto taką… posiadać ? Ja korzystam z faktu, że jest już na moim klastrze HDP. W domowym zaciszu najłatwiej postawić kolejny kontener dockerowy. No i nie zapomnij o dodaniu topic-a.
DAG
import json
from datetime import timedelta
from datetime import datetime
import airflow
from airflow import DAG
from airflow.operators.http_operator import SimpleHttpOperator
from airflow.operators.python_operator import PythonOperator
from airflow.models import Variable
from kafka import KafkaProducer
default_args = {
'owner': 'Maciej Szymczyk',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(0),
'email': ['maciej.szymczyk@outlook.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
}
dag = DAG('ztm_gps_collector', description='Collects busses and trams GPS and send them to kafka ',
schedule_interval=timedelta(seconds=10), default_args=default_args)
api_key = Variable.get("api_key")
resource_id = 'f2e5503e927d-4ad3-9500-4ab9e55deb59'
t1 = SimpleHttpOperator(
task_id = 'get_busses_gps',
http_conn_id = 'url_ztm_gps',
endpoint = 'api/action/busestrams_get/',
method = 'GET',
data = {"type": "1", 'resource_id': resource_id, 'apikey' : api_key},
xcom_push = True,
dag=dag,
provide_context = True,
)
def send_to_kafka(**kwargs):
t1 = kwargs['ti']
gpses = json.loads(t1.xcom_pull())
producer = KafkaProducer(bootstrap_servers=['10.7.35.110:6667'],
value_serializer=lambda x:
json.dumps(x).encode('utf-8'))
for record in gpses["result"]:
print(record)
future = producer.send('ztm_gps', value=record)
result = future.get(timeout=60)
t2 = PythonOperator(task_id='send_gps_to_kafka', python_callable=send_to_kafka, dag=dag, provide_context=True)
t1 >> t2
Kod nie jest specjalnie skomplikowany. W przypadku SimpleHttpOperator należy pamiętać o tym, by przekazywał obiekt xcom do kolejnego zadania. PythonOperator używając xcom_pull() pobiera wartość z poprzedniego zadania. Warto rozważyć dodanie adresu Kafki jako zmienna (czego nie zrobiłem ?)
Jeżeli niczego nie pomieszaliśmy, to nasz DAG powinien pojawić się w web apce.

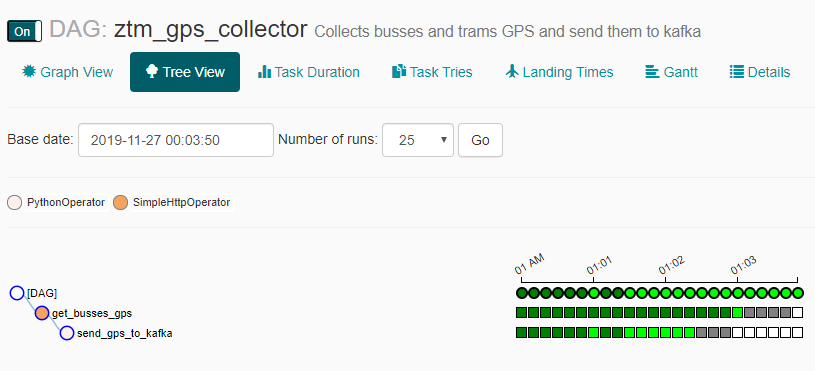
Po włączeniu naszego DAG-a docelowo mamy zobaczyć zielone pola i ruch na Kafce ?. Do szybkiego podejrzenia co jest w danym topicu użyłem Conductora
Co dalej?
Można powiedzieć, że mamy jako taki strumień danych. Teraz na jego podstawie możemy obliczyć np. prędkość lub przejechany dystans. Przydałaby się też wizualizacja pozycji pojazdów na mapie. Masz jakiś pomysł? Podziel się w komentarzu ?

Dlaczego nie Apache Beam zamiast Sparka? Wtedy możesz skorzystać z Dataflow i nie musisz utrzymywać klustra.
Kolejna sprawa to wydaje mi się, że catchup warto ustawić na True, skonfigurować, że tylko jedno pobieranie danych może się odbywać w czasie – pool z wartościa.
Nie jest zalecane wykorzystanie klasy Variables bezpośrednio w DAGu, ale powinno się korzystać z Ninja Templates, ponieważ ma to impact na wydajność.
Dzięki za uwagi odnośnie Apache Airflow. Nadrobię zaległości 🙂 dopiero się go uczę.
Co do Spark vs Apache Beam: Zaczynam od Sparka bo mam w nim najwięcej doświadczenia, a klaster to nie problem. Dodaję Apache Beam + Dataflow do TODO listy.
Puściłeś to na dłużej? Ja napisałem kawałek skrypty w Pythonie zapisującego do SQLite (repo https://github.com/prokulski/autobusy_tramwaje) i po jakiejś dobie dostaję za każdym razem z API {‘result’: ‘Błędna metoda lub parametry wywołania’}. Wygląda jakbym przekroczył jakieś limity, ale nie doszukałem się na stronie nic na ten temat.
Nie zbierałem dłużej niż dobę. Widzę, że robisz 2 zapytania co 30 sekund, czyli rzadziej niż ja. Aktualnie mam mały problem z moim klasterem, ale jak do tego wrócę to Dam Ci znać.
Jaki masz hardware do dyspozycji? Czy na laptopa można zbudować jakieś sensowne środowisko? Oczywiście to testów i uczenia się :).
Hej. Mam do dyspozycji PC, laptopa, mały klaster maszyn wirtualnych na uczelni i subskrypcję Visual Studio na Azure, ale większość rzeczy robie na laptopie ?. W tym wpisie wspomniałem jak Docker może pomóc: https://wiadrodanych.pl/docker/docker-na-pomoc/