

W poprzednim poście utworzyliśmy strumień danych lokalizacji pojazdów komunikacji miejskiej na jednym z topiców w Apache Kafka. Teraz dorwiemy się do tego strumienia z poziomu Apache Spark, zapiszemy trochę danych na HDFS i zobaczymy czy da się coś z nimi zrobić.
Dla przypomnienia, wpis jest częścią mini projektu związanego z danymi lokalizacji pojazdów komunikacji miejskiej w Warszawie. Plan na dzień dzisiejszy poniżej, a zastanawiamy się nad jego środkiem => Apache Spark

Odczyt z Kafki
Najszybszą metodą odpalenia strumienia był kod w Pythonie, w którym użyłem PySparka. Hostname, port i topic są podawane jako parametry. Cała sztuka odczytu z kafki są to linie od 23 do 28. Rezultat wyświetlany jest na konsolę.
import sys
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
if __name__ == "__main__":
if len(sys.argv) != 4:
print("Usage: spark-submit ztm_streaming.py <hostname> <port> <topic>")
exit(-1)
host = sys.argv[1]
port = sys.argv[2]
topic = sys.argv[3]
spark = SparkSession\
.builder\
.appName("ZTM")\
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
ztm_raw = spark.readStream\
.format("kafka")\
.option("kafka.bootstrap.servers", host + ":" + port)\
.option("subscribe", topic)\
.load()
ztm_raw = ztm_raw.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
query = ztm_raw.writeStream\
.outputMode("append")\
.format("console")\
.option("truncate", "false")\
.trigger(processingTime="5 seconds")\
.start()\
.awaitTermination()
Efekt widać poniżej. Klucza żadnego nie ma, więc można go pominąć. Wartością jest natomiast JSON, który warto zdeserializować i rozbić na kolumny.

Deserializacja JSON-a i zapis na HDFS
Oprócz doprowadzenia danych do sensownej postaci, chcę je też zapisać na HDFS. Spark Streaming działa na zasadzie micro-batchy. Zacznijmy od zwykłego batch-a, a potem… potem będziemy się martwić co dalej ?.
Do poprzedniego skryptu dopisałem użycie funkcji from_json, która (jak sama nazwa wskazuje) robi coś z json-a ?. Potrzebny jest też schemat. Potem jest już zwykły select, by kolumny ładnie się prezentowały. Linie 31-38.
Zapis do HDFS to koniec skryptu. Warto zwrócić uwagę, że dane materializowane były co godzinę, by uniknąć problemu małych plików.
import sys
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
if __name__ == "__main__":
if len(sys.argv) != 4:
print("Usage: spark-submit m03_demo05_tweetSentimentCount.py <hostname> <port> <topic>")
exit(-1)
host = sys.argv[1]
port = sys.argv[2]
topic = sys.argv[3]
spark = SparkSession\
.builder\
.appName("ZTM_1h")\
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
ztm_raw = spark.readStream\
.format("kafka")\
.option("kafka.bootstrap.servers", host + ":" + port)\
.option("subscribe", topic)\
.load()
ztm_raw = ztm_raw.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
jsonSchema = StructType([ StructField("Lat", DoubleType(), True),
StructField("Lon", DoubleType(), True),
StructField("Time", TimestampType(), True),
StructField("Lines", StringType(), True),
StructField("Brigade", StringType(), True)
])
ztm_raw = ztm_raw.withColumn("json", from_json(ztm_raw["value"], jsonSchema))
ztm_raw = ztm_raw.select(\
col('json.Lat').alias('lat'),\
col('json.Lon').alias('long'),\
col('json.Time').alias('time'),\
col('json.Lines').alias('lines'),\
col('json.Brigade').alias('brigade'),\
)
ztm_raw.writeStream\
.outputMode("append")\
.trigger(processingTime="1 hour")\
.format("parquet")\
.option("path", "/data/ztm_raw")\
.option("checkpointLocation", "/data/ztm_raw_checkpoint")\
.start()\
.awaitTermination()
Obliczanie prędkości
Przez kilkanaście godzin zebrało się około 90 MB danych. Nie jest to dużo, ale do przygotowania skryptu pod Spark Streaming wystarczy. Tym razem przałączyłem się na Apache Zeppelin i Scale. Po załadowaniu parquet do zmiennej ztm oto co widzimy.
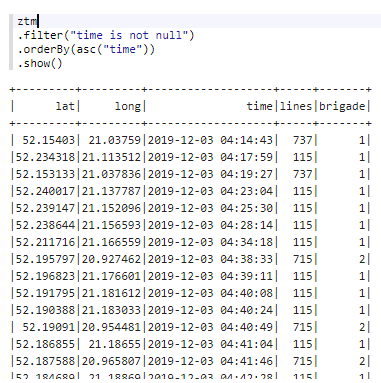
Chcę obliczyć prędkość na podstawie poprzedniej pozycji GPS. Do tego trzeba będzie użyć Window Functions razem z funkcją lag. Sposób obliczenia dystansu między dwoma Lat Long-ami wziąłem z tego Github Gist-a. Skoro już ktoś się napracował… ?.
Potrzebny będzie obiekt z “oknem”. Grupy rekordów identyfikujemy po lines i brigade, a porządkujemy je na podstawie czasu.
val w = org.apache.spark.sql.expressions.Window
.partitionBy("lines","brigade")
.orderBy("time")
ztm
.where("time is not null and lines != 121")
.withColumn("prev_lat", lag("lat", 1, 0).over(w))
.withColumn("prev_long", lag("long", 1, 0).over(w))
.withColumn("prev_time", lag("time", 1).over(w))
.withColumn("a", pow(sin(toRadians($"lat" - $"prev_lat") / 2), 2) + cos(toRadians($"prev_lat")) * cos(toRadians($"lat")) * pow(sin(toRadians($"long" - $"prev_long") / 2), 2))
.withColumn("distance", atan2(sqrt($"a"), sqrt(-$"a" + 1)) * 2 * 6371)
.withColumn("time_diff", unix_timestamp($"time") - unix_timestamp($"prev_time"))
.withColumn("speed", $"distance"/$"time_diff" * 3600)
.show()
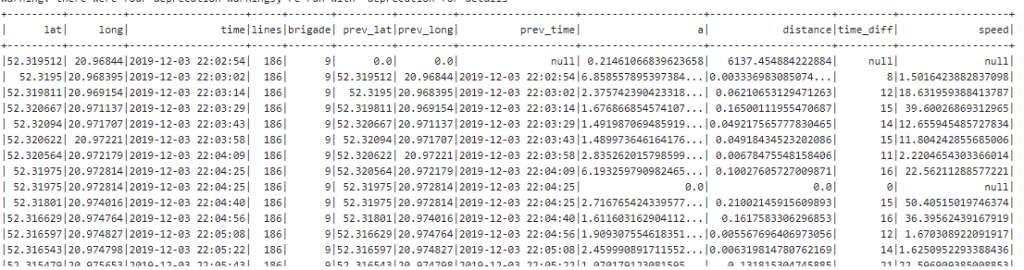
Prędkość wygląda sensownie. Kolejny krok, oprócz odrzucenia niepotrzebnych kolumn, to wyświetlenie najnowszej wartości dla każdego pojazdu. Tutaj również przyda się Window Functions. Tym razem interesuje nas sortowanie po czasie od najwyższej wartości.
val w2 = org.apache.spark.sql.expressions.Window
.partitionBy("lines","brigade")
.orderBy(desc("time"))
ztm
.where("time is not null")
.withColumn("prev_lat", lag("lat", 1, 0).over(w))
.withColumn("prev_long", lag("long", 1, 0).over(w))
.withColumn("prev_time", lag("time", 1).over(w))
.withColumn("a", pow(sin(toRadians($"lat" - $"prev_lat") / 2), 2) + cos(toRadians($"prev_lat")) * cos(toRadians($"lat")) * pow(sin(toRadians($"long" - $"prev_long") / 2), 2))
.withColumn("distance", atan2(sqrt($"a"), sqrt(-$"a" + 1)) * 2 * 6371)
.withColumn("time_diff", unix_timestamp($"time") - unix_timestamp($"prev_time"))
.withColumn("speed", $"distance"/$"time_diff" * 3600)
.withColumn("row_number", row_number.over(w2))
.filter("row_number = 1")
.select("lat","long","time","lines","brigade","distance","speed")
.show()
Użycie row_number i pofiltrowanie po 1 załatwia sprawę. Efekt wygląda całkiem nieźle.

Co dalej?
Kolejnym krokiem będzie implementacja Spark Streaming na podstawie tego co powyżej. W komentarzach poprzedniego wpisu padł też ciekawy pomysł z użyciem Apache Beam (to kiedyś). Zastanawiam się też gdzie kierować przetworzone dane. Czy z powrotem na Kafkę, czy na jakąś bazę np. HBase, Cassandra itp. Wszelkie uwagi i pomysły mile widziane ?

Ładowanie wszystkich funkcji do przestrzeni nazw za pomocą “from library import *” jest odradzane przez PEP8 i pyspark jest idealnym przykładem dlaczego – niektóre pythonowe funkcje (tj. sum, min, max) są przeładowywane pysparkowymi odpowiednikami i stają się źródłem potencjalnych, trudnych do zlokalizowania bugów.
Poza tym powodzenia – wpadłeś na świetny pomysł 🙂
Dzięki za info. Miałem kiedyś podobną sytuację w angularze gdy VS Code zaimportował mi nie tą biblioteke co trzeba ? potem człowiek szuka dziury w całym
Szkoda, że w Warszawie są buspasy. Mógłbyś stworzyć informacje o korkach.