

Korzystanie z HDFS bardzo przypomina korzystanie ze zwykłego systemu plików z użyciem terminala. Grupy, uprawnienia, pliki, foldery itp. Bawiąc się kolejnymi technologiami Big Data można zapomnieć się i potraktować HDFS jak zwykły dysk.
Dane
W ostanim wpisie wspomniałem kilkanaście źródeł danych. Na jednym z nich znalazłem Enron Email Dataset. Jest to zbiór maili przedsiębiorstwa energetycznego Enron. Co takiego charakteryzuje ten zbiór? Zawiera dużo małych plików.
Jak dużo?
Ściągnąłem, rozpakowałem i wyszło że plików jest ponad pół miliona.
find . | wc -l
#520901
Ale nie są zbyt duże i łącznie na HDFS zajęły 1.3 GB

Pliki są dość małe
Jakich?
Poniżej zamieściłem fragment jednego z plików. Jak widać jeden plik to jedna wiadomość. Przetwarzanie każdej linii osobno dużo nam nie da. Trzeba uważać na pole “To:”. Czasami nie występuje, a czasami posiada wiele adresatów i zajmuje więcej niż jedną linię.
Message-ID: <29790972.1075855665306.JavaMail.evans@thyme>
Date: Wed, 13 Dec 2000 18:41:00 -0800 (PST)
From: 1.11913372.-2@multexinvestornetwork.com
To: pallen@enron.com
Subject: December 14, 2000 - Bear Stearns' predictions for telecom in Latin
America
Mime-Version: 1.0
...
Do rzeczy
Tak samo jak w przypadku półtora miliarda haseł, wrzuciłem dane na HDFS i zacząłem pisać program w Spark-u na podstawie jednego pliku. Program opierał się na podziale tekstu na linie i wykorzystanie regex-ów. Myślałem o tym by docelowo utworzyć model pod graf w GraphFrames i zobaczyć co zwróci mi PageRank lub Label Propagation Algorithm.
java.lang.OutOfMemoryError
Niestety, podejście pierwsze nieudane. Można pokombinować z konfiguracją JVM, ale widać ewidentnie, że coś jest na rzeczy. Danych jest w końcu tylko 1,3 GB. Byle smartfon zmieściłby tyle danych do pamięci.

Czwany foreach
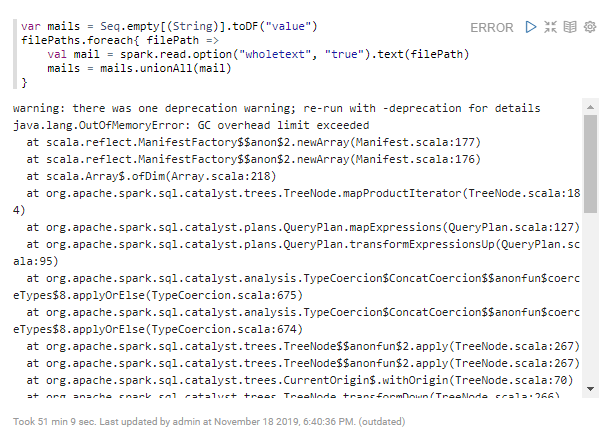
Czwany programista potrafi korzytsać z foreach-a. Podejście drugie również nieudane. Przecież w Spark-u jest lazy evaluation i DataFrame to tak naprawdę abstrakcja czyli metadane (a ich jest dość sporo).
Zapis do pliku
Skoro nie możemy wczytać całego zbioru naraz, zapiszmy wszystko po kolei. W końcu piszą że Parquet jest dobry.
filePaths.foreach{ filePath =>
val mail = spark.read.option("wholetext", "true").text(filePath)
mail.write.mode("append").parquet("/data/mails_parquet")
}
Tym razem bez wyjątku, ale efekt jest mało satysfakcjonujący. Operacja ta jest bardzo niewydajna. Po dniu pracy w folderze znalazło się około 9400 rekordów… w około 9400 plikach ?, a co dopiero pół milona.
Merge do jednego pliku
Istnieje taka komenda w HDFS jak getmerge. Niestety poruszany tutaj zbiór danych to jeden plik = jeden rekord, w dodatku ze znakami następnej linii, dlatego nie nadaje się w tym przypadku.
Powód
HDFS, a dokładnie to NameNode, buforuje wszystkie nazwy pliki i adresy bloków w pamięci (Po ludzku: wie co i gdzie leży). Dzięki takiemu mechanizmowi HDFS jest szybki.
Duża ilosć plików oznacza dużą ilość metadanych, którą musi ogarnąć JVM.
Możemy wyświetlić liczbę bloków danego pliku/katalogu w HDFS poniższą komendą
hadoop fsck [path] [options]
Porównajmy 1.3 GB maile z ważącym ponad 70 GB plikiem JSON z wycieku haseł
| Maile (1.3 GB) | Hasła (72.3 GB) | |
| Bloki | 505427 | 579 |
| Średnia wielkość bloku | 2,75 KB | 134 MB |
Wyniki mówią same za siebie ?
Wnioski
Wpis ten, pisany pół żartem pół serio, pokazuje że nie można tak po prostu wrzucić wiadra danych (?) do HDFS-a. Rozwiązaniem tego problemu jest wstępne przetworzenie danych przed wrzuceniem. W głowie mam pomysł by użyć przetwarzania strumieniowego w Sparku-u z wykorzystaniem Apache Kafka.
A Ty jak byś podszedł/podeszła do tego problemu? Podziel się w komentarzu ?

Cześć Maciej,
ciekawy temat, ale z artykułu chyba nie do końca wynika co na celu ma to ćwiczenie. Co chcesz osiągnąć? Czytelnicy, którzy nie zajmują się na co dzień tematyką BigData (a ja do takich należę, chociaż coś tam wiem na ten temat) mogą nie wiedzieć o co chodzi. Poza tym wydaje mi się, że opisujesz wszystko trochę skrótowo.
Skąd ten OutOfMemoryError ? OutOfMemoryError nie bierze się przecież z ilości plików, no chyba, że próbujesz wczytać wszystkie na raz do pamięci. Ok, chyba tak robisz? Tak?
Hm, nie rozumiem też jak chcesz wykorzystać Kafkę, to broker wiadomości?
Jak bym ja to rozwiązał? Nie pchałbym tych danych do HDFSa, bo po co skoro jest ich tylko 1.3 GB. Hadoop chyba lepiej przetwarza duże pliki (dużą ilość danych).
Co do wstępnej obróbki, to można wyciągnąć to co nas interesuje z tych plików i zapisać do jednego “wielkiego” pliku. Nie wiem co chcesz wyciągać z tych maili, albo w jakim celu je przetwarzasz,więc ciężko coś powiedzieć.
Jeśli chcesz analizować treść możesz znaki końca linii zamienić na jakiś inne znaki lub je w ogóle wyciąć lub zamienić na spacje. Wtedy masz jeden mail w jednym wierszu. Nie wiem czy takie rozwiązanie by się sprawdziło, ale znaki końca linii nie są aż tak istotne dla analizy tekstu?
Hej, dzięki za komentarz.
Celem była zabawa/poznanie technologii Big Data. Szukam różnych zbiorów danych/problemów i staram się je skonfrontować z technikami przetwarzania dużych danych. Zbiór ma 1.3 GB i w praktyce nikt by nie uruchamiał Hadoop-a itp. Prosty skrypt w Pythonie połknąłby go w całości. Jednak możemy sobie wyobrazić, że pracujemy w NSA i mamy do przemielenia o wiele więcej maili a 1.3 GB to tylko próbka :-). Staram się przekazywać na blogu ciąg myślowo-przyczynowo-skutkowy, więc faktycznie czasami mogę opisać coś skrótowo. Zależy mi na tym, by opisać drogę. Np. że tutaj coś nie wyszło, więc poszedłem w inną stronę itp.
Co do OutOfMemoryError: owszem do pamięci wczytywane są wszystkie na raz… metadane :-), czyli na którym DataNode znajduje się dany blok danych. A że były to małe pliki, więc 1 plik = 1 blok. Widać to w porównaniu z dużym JSON-em, gdzie bloki są normalnych rozmiarów.
Kafkę wymieniłem pod kątem przetwarzania strumieniowego. Twój pomysł wydaje mi się spoko. Myślałem o tym, by wyciągnąć informacje: id, od kogo, do kogo, temat i utworzyć model grafowy w GraphFrame lub Neo4j.
Mam nadzieję, że odpowiedziałem na Twoje pytania. Jak coś to pisz 🙂
Super 😉 Dzięki za odpowiedź.