

Myślałeś/aś kiedyś o utworzeniu strumienia z operacji w bazie danych? W tym wpisie dowiesz się czym jest Change Data Capture i jak go wykorzystać planując architekturę naszego systemu. W części praktycznej sprawdzimy działanie Debezium na bazie MySQL
Co to jest Change Data Capture?
Change Data Capture to proces wykrywania zmian dokonywanych w bazie danych. Takie zmiany potem możemy strumieniowo aplikować w innych bazach, przetwarzać, zapisywać i na nie reagować. Innymi słowy: otrzymujemy strumień zdarzeń z naszej bazy danych.
Umożliwia nam to szybsze i precyzyjne decyzje oparte na danych (Stream Processing i Streaming ETL). Nie obciąża systemów i sieci tak jak klasyczne rozwiązania. Często jest to jedyne sensowne rozwiązanie umożliwiające modernizacje systemów legacy.
Rodzaje Change Data Capture
Query-Based
Czy jeśli będę pytał co 5 sekund bazę danych o konkretną tabelę, to jest to Change Data Capture? Na swój sposób tak, ale ma swoje minusy.
- Wymaga odpowiedniego przygotowania tabeli: kolumna z czasem modyfikacji rekordu oraz mechanizm aktualizacji tego pola
- Nie wykrywamy wszystkich operacji. W przypadku usuwania rekordów, musimy zastosować trick soft delete, czyli zaznaczyć rekord flagą do usunięcia, a fizycznie usunąć go później innym mechanizmem
- Nie wykrywamy zmiany w strukturze tabeli
- Możemy nadmiernie obciążyć pytaniami bazę danych lub sieć, jeśli danych jest sporo
- Nie wykrywamy poprzedniego stanu w którym był rekord.
Czy tyle minusów skreśla wykorzystanie tego sposobu? To wszystko zależy od kontekstu. Logstash’em można w ten sposób synchronizować bazę z Elasticsearch’em. Jeśli nam to wystarcza, nie ma sensu utrzymywać kolejnych technologii.
Log-Based
Generalizując, bazy danych zapisują wszystkie transakcje i modyfikacje bazy w transacation log‘u. Jest to kluczowy element. W przypadku awarii pozwala na powrót do spójnego stanu.
Czytając taki log wykrywamy wszystkie operacje zapisu, zmiany i usunięcia rekordów, a także zmiany schematu tabel. Takie dane możemy wysyłać od razu lub paczkami. Obciążenie bazy jest znikome, a na pewno mniejsze niż w przypadku Query-Based CDC.
Każda baza na swój sposób podchodzi do Change Data Capture. Tutaj znajdziesz informacje jak to robi SQL Server. W dalszej części artykułu użyjemy Debezium, otwartej i rozproszonej platformy CDC.
Jak mogę to wykorzystać?
Zapis do wielu źródeł
Zaczynamy z prostą aplikacją i pojedynczą bazą danych. Z czasem dochodzi cache (Redis, Memcached), silnik wyszukiwarki (Elasticsearch, Solr), kolejki (Kafka, RabbitMQ), mikroserwisy i wiele baz (Polyglot Persistence).
Ostatecznie, generowane dane mają wielu adresatów. Wysyłanie rekordu do wszystkich baz przez jeden serwis komplikuje logikę i utrudnia zachowanie spójności (Two Phase Commit też ma swoje bolączki). Na implementację architektury zdarzeniowej (Event Sourcing) w aplikacji może być już za późno. W takiej sytuacji Change Data Capture “całe na biało”.
Integracja baz danych
Widziałes/aś kiedyś “integrację” danych między bazami na zasadzie SELECT * FROM table ? Ja tak. Nie wiedziałem czy śmiać się czy płakać 😉. Change Data Capture sprawdzi się też w tym przypadku. Na pewno o wiele mniej inwazyjnie.
ETL i Stream Processing
Utworzenie strumienia z bazy danych otwiera nam drogę do przetwarzania strumieniowego w procesach ETL. Architektura typu lambda lub kappa przyśpieszają procesy decyzyjne. Dodatkowo, nie wszystkie operacje można zrównoleglić. Z Prawa Amdahla wiemy że nawet w większości zrównoleglony kod nie skalują się liniowo. Podejście strumieniowe rozciąga przetwarzanie w czasie co ma pozytywny wpływ na utylizację zasobów.
Debezium
Debezium to otwarta i rozproszona platforma CDC. W praktyce jest to zbiór connectorów do Kafka Connect, a co z tym się wiąże, rozwiązanie oparte jest o Apache Kafka. Mamy do dyspozycji konektory do MySQL, PostgreSQL, MongoDb, Cassandra, SQL Server, Oracle, Db2 i Vitesse.
Środowisko
Im nowsze systemy, tym uruchomienie Hello World’a staje się trudniejsze i wymaga coraz więcej klocków 😅. Posłużymy się Docker Compose, a w nim:
- Zookeeper
- Apache Kafka
- AKHQ – Webowe GUI do Kafki
- Kafka Connect z Debezium
- MySQL w wersji 8
version: '2'
services:
zookeeper:
image: 'docker.io/bitnami/zookeeper:3-debian-10'
ports:
- '2181:2181'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: 'docker.io/bitnami/kafka:2-debian-10'
ports:
- '9092:9092'
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,PLAINTEXT_HOST://:29092
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
depends_on:
- zookeeper
connect:
image: debezium/connect:1.4
ports:
- 8083:8083
environment:
- STATUS_STORAGE_TOPIC=my_connect_statuses
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- CONFIG_STORAGE_TOPIC=my_connect_configs
- GROUP_ID=1
- BOOTSTRAP_SERVERS=kafka:9092
akhq:
image: tchiotludo/akhq
environment:
AKHQ_CONFIGURATION: |
akhq:
connections:
docker-kafka-server:
properties:
bootstrap.servers: "kafka:9092"
connect:
- name: "connect"
url: "http://connect:8083"
ports:
- 8080:8080
links:
- kafka
- zookeeper
mysql:
image: mysql:8
ports:
- 3306:3306
environment:
MYSQL_DATABASE: 'school'
MYSQL_USER: 'user'
MYSQL_PASSWORD: 'password'
MYSQL_ROOT_PASSWORD: 'password'
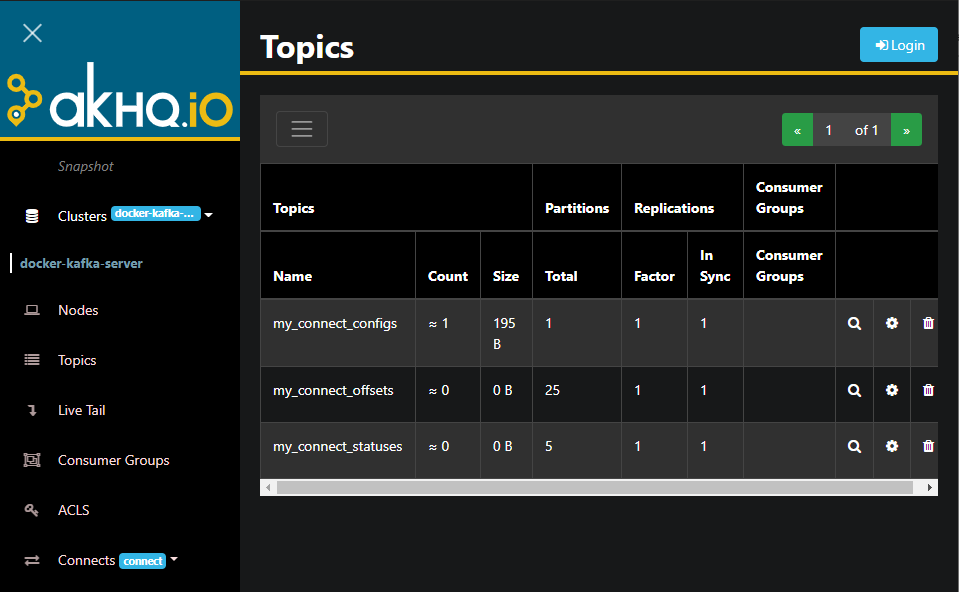
Konfiguracja Debezium MySQL w Kafka Connect
Kafka Connect poświęciłem osobny artykuł. Skoro już mamy AKHQ, spróbujmy coś wyklikać.

Wykorzystana konfiguracja znajduje się poniżej. AKHQ podpowiada nam wszystkie możliwe opcje razem z opisami.
tasks.max = 1 database.history.kafka.topic = schema-changes.school database.hostname = mysql database.user = user database.password = password database.server.name = school database.include.list = school database.history.kafka.bootstrap.servers = kafka:9092
Jeśli konfiguracja jest poprawna to powinniśmy zobaczyć zielony status conenctora, nowe topic’ki w Kafce i “pozytywne” logi


onnect_1 | 2021-01-10 17:42:06,243 INFO MySQL|school|task Creating thread debezium-mysqlconnector-school-binlog-client [io.debezium.util.Threads] connect_1 | 2021-01-10 17:42:06,246 INFO MySQL|school|task Creating thread debezium-mysqlconnector-school-binlog-client [io.debezium.util.Threads] connect_1 | Jan 10, 2021 5:42:06 PM com.github.shyiko.mysql.binlog.BinaryLogClient connect connect_1 | INFO: Connected to mysql:3306 at binlog.000001/156 (sid:5793, cid:14) connect_1 | 2021-01-10 17:42:06,262 INFO MySQL|school|binlog Connected to MySQL binlog at mysql:3306, starting at binlog file 'binlog.000001', pos=156, skipping 0 events plus 0 rows [io.debezium.connector.mysql.BinlogReader] connect_1 | 2021-01-10 17:42:06,262 INFO MySQL|school|task Waiting for keepalive thread to start [io.debezium.connector.mysql.BinlogReader] connect_1 | 2021-01-10 17:42:06,263 INFO MySQL|school|binlog Creating thread debezium-mysqlconnector-school-binlog-client [io.debezium.util.Threads] connect_1 | 2021-01-10 17:42:06,363 INFO MySQL|school|task Keepalive thread is running [io.debezium.connector.mysql.BinlogReader]
Dodanie danych do MySQL
Dobrać się do konsoli MySQL w Docker Compose możemy poniższą komendą.
sudo docker-compose exec mysql mysql -uroot -p
Sensowność danych w tym przypadku nie ma znaczenia. Wziąłem gotowe kawałki SQL z integracji Logstash’em bazy MySQL z Elasticsearch z mojego kursu.
use school;
CREATE TABLE IF NOT EXISTS groups(
group_id int(11) NOT NULL AUTO_INCREMENT,
group_number char(4) NOT NULL,
description VARCHAR(100),
something_important int(11),
modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (group_id),
KEY group_number (group_number)
) ENGINE=InnoDB;
INSERT INTO groups
(group_number, description, something_important)
VALUES
('1A','some group',100),
('2A','some group',102),
('3A','some group',101),
('1B','some group',123),
('2B','some group',133),
('3B','some group',144);
UPDATE school.groups
SET
description = 'updated'
WHERE
group_id % 2 = 0;
GIF z działania connectora
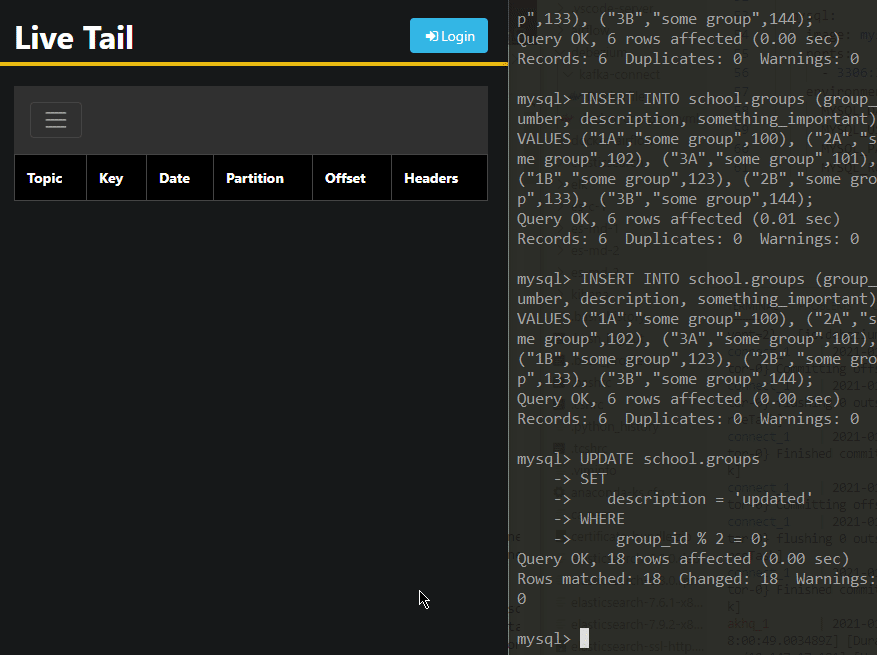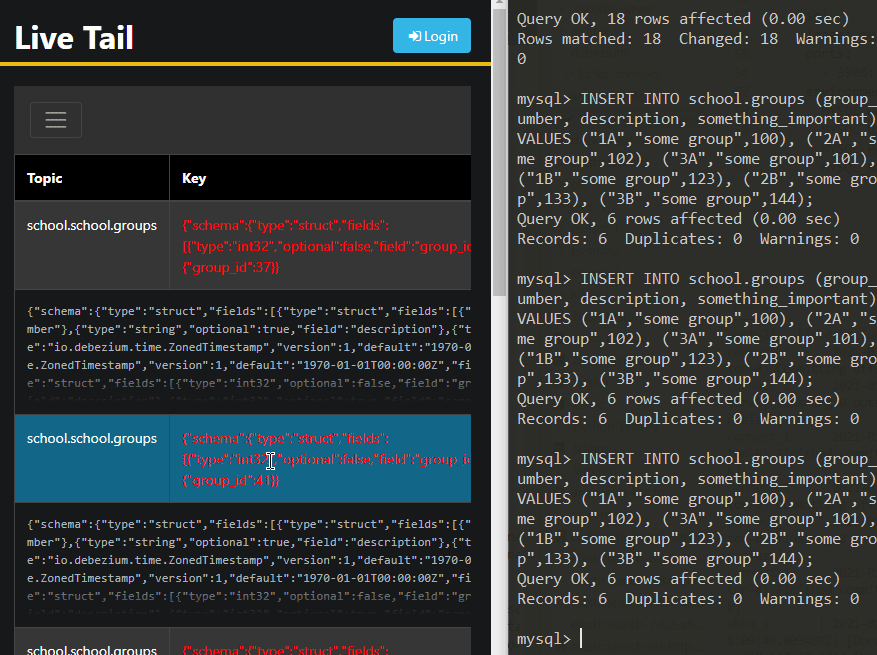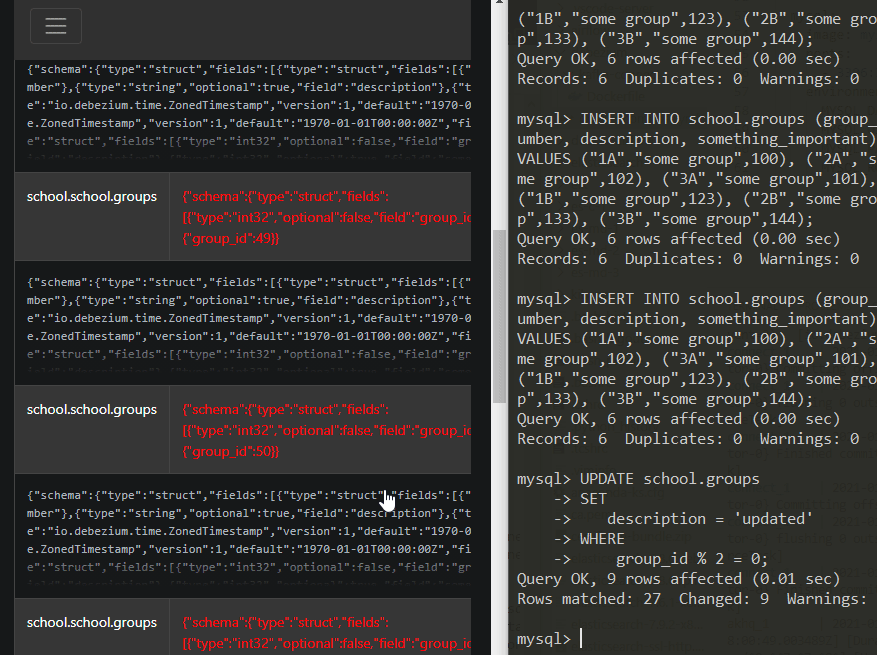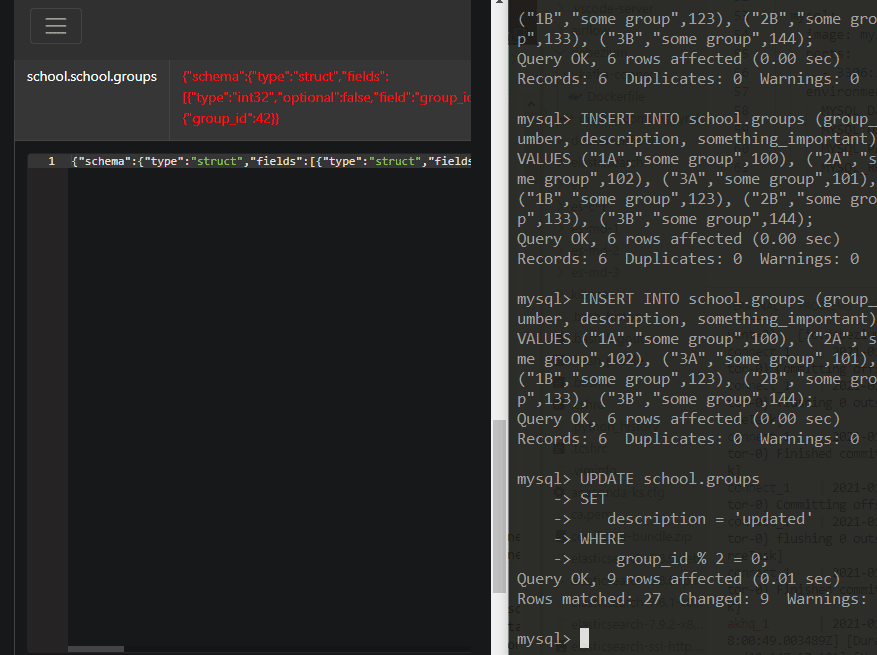
Podsumowanie
Jak właśnie się przekonałeś/aś, CDC w Debezium nie jest takie trudne, a otwiera sporo możliwości. Czasami będą potrzebne drobne aplikacje po stronie serwera (np. PostgreSQL lub Cassandra). Jeśli zainteresował Cię ten temat, warto posłuchać podcastu od Confluent. Wypowiada w nim współautor Debezium.

Cześć,
wydaje mi się, że jest jakiś błąd w komunikacji. Utknąłem na utworzeniu definicji.
Dostaje następujący komunikat:
Connector configuration is invalid and contains the following 1 error(s): Unable to connect: Public Key Retrieval is not allowed You can also find the above list of errors at the endpoint `/connector-plugins/{connectorType}/config/validate`
Na screenie widzę, że podany w konfiguracji jest user “root” a w listingu user “user”. Który z nich jest prawidłowy?
Wydaje mi się że w przykładzie (z lenistwa) użyłem root’a. Nie chciało mi się bawić uprawnieniami.
Wydaje mi się że Twoj problem ma związek z TLS w MySQL.
https://stackoverflow.com/questions/50379839/connection-java-mysql-public-key-retrieval-is-not-allowed