

Systemy są coraz większe, rozproszone i skomplikowane. W tym wpisie poruszona jest kwestia monitoringu. Dlaczego jest ważny i co możemy monitorować.
A na co to komu potrzebne?
Świadomość
Nawet najdalszą podróż zaczyna się od pierwszego kroku.
Lao-tzu
Podjęcie tematu monitoringu możemy zacząć od dwóch prostych pytań:
- Co mogę monitorować?
- Co chcę monitorować?
Pytania są bardzo podobne, dlatego czym prędzej wyjaśniam o co mi chodzi 😊.
Pierwsze pytanie odnosi się do identyfikacji. Możemy mieć pod swoją opieką od serwerów, po urządzenia sieciowe, a na serwisach, kontenerach i maszynach wirtualnych kończąc. Gdy środowisko jest małe, pozornie wydaje nam się że wszystko jest pod kontrolą. Gdy urośnie, pamięć bywa zawodna.
Druga kwestia dotyczy ustalenia priorytetów. Inne wymagania będzie mieć administrator infrastruktury i sieci, inny inżynier danych, a jeszcze inny programista. Oczywiście nie jest tak, że każda osoba w firmie utrzymuje osobny monitoring. Po prostu bez sensu zbierać wszystko (bo to niepotrzebny koszt). Czasami warto też zapytać kolegów z zespołu obok czy nie przydałby im się jakiś dashboard.
Diagnostyka
Znasz Fallacies of distributed computing? Jest to zbiór błędnych założeń, które mają programiści zaczynający pracę z systemami rozproszonymi, czyli:
- Sieć jest niezawodna;
- Nie ma opóźnień;
- Przepustowość jest nieograniczona;
- Sieć jest bezpieczna;
- Topologia się nie zmienia;
- Jest tylko jeden administrator;
- Koszty transportu są równe zero;
- Sieć jest homogeniczna.
Brzmi znajomo 😉? Okazuje się, że rzeczywistość jest bardziej złożona. Gdy wszystko działa nie ma się czym przejmować. Gdy coś przestanie działać… bez monitoringu działamy na oślep. Proste zbieranie logów z wyjątkami w aplikacji może zaoszczędzić godziny debugowania. Wyszukiwanie wąskich gardeł można zacząć od zbierania najprostszych metryk z serwerów i maszyn wirtualnych.
“Ale to nie moja wina”
Założenie “jest tylko jeden administrator” bywa tak samo prawdziwe jak “wszyscy pracują w jednym zespole”. Niedawno miałem problem z wysoką utratą pakietów, retransmisjami i opóźnieniami w klastrze Elasticsearch. Bez monitoringu:
- Nie wykryłbym tego problemu;
- Nawet jakbym go wykrył, ciężko było by mi przekonać zespół odpowiedzialny za sieciówkę, że taki problem w ogóle istnieje;
- Problem pewnie istniałby do dziś.
Czasami zawini switch, czasami wkładka, czasami kabel, czasami człowiek, co też jest naturalne. Trzeba naprawić problem, a nie szukać kozła ofiarnego.
Wykrywanie problemów przed ich wystąpieniem
Skończyło Ci się kiedyś miejsce na dysku? Logi zapchał serwer? Ten i wiele innych problemów można po prostu uniknąć. Każda awaria to pewna lekcja. Nie raz słyszałem że dany wykres czy metryka w dashboardzie jest wynikiem problemu który kiedyś wystąpił.
Cyberbezpieczeństwo
Systemy są coraz większe, rozproszone i skomplikowane. Nie raz słyszymy o ataku ransomware, wycieku danych, przejęciach kont i karach związanych z RODO. Nie bez powodu cyberbezpieczeństwo jest dzisiaj jednym z kluczowych tematów, nie tylko w dużych firmach i instytucjach.
Czy wiesz ile było nieudanych prób logowania na Twój serwer? Jak sprawdzisz, czy Twój serwer pocztowy nie padł ofiarą ataku? Spory ruch sieciowy z firmowej bazy do internetu… ciekawe 😋.
Niestety w tym przypadku również nie w sposób zbierać wszystko (a tym bardziej na to reagować). Najpopularniejszym sposobem na określenie istotnych wektorów ataku jest MITRE ATT&CK. Jest to baza wiedzy bogata w taktyki i techniki stosowane przez hakerów. Inaczej podejdziemy do ochrony stacji Windows, a inaczej do zasobów w chmurze.
Decyzje oparte na danych
Aplikacja wolno działa. To na pewno procesor. Zwiększmy liczbę rdzeni.
Nadal to samo… to dajmy więcej pamięci RAM.
Hmm dziwne… niech firma kupi dyski NVMe SSD. Przecież to musi być to.
A potem okazuje się, że wirtualka była wpięta do interfejsu 1G zamiast 10G 😏.
Nie raz przekonałem się że moja “pierwsza diagnoza”, była błędna po spojrzeniu w metryki.
Optymalizacja i przwidywanie kosztów
Im lepsze mamy dane, tym (prawdopodobnie) lepsze możemy podejmować decyzje. Z perspektywy biznesu wszystko sprowadza się do pieniędzy. Podejmując trafne decyzje zmniejszamy koszty i zwiększamy zyski.
Co możemy monitorować?
CPU
Większość osób kojarzy monitorowanie pracy procesora z wartościami od 0 do 100%. Wartość ta może dotyczyć wszystkich rdzeni (wartość znormalizowana) lub każdego z osobna. Warto jednak wiedzieć o poszczególnych kategoriach zużycia procesora. Spotkasz je np. używając komendy top lub htop w systemach Linux.
system– ilość czasu procesora używana przez kernel. Są to niskopoziomowe zadania takie jak alokacja pamięci, procesy systemowe, komunikacja między procesami, praca systemu plików.user– ilość czasu procesora używana przez procesu w przestrzeni użytkownika. Może być to aplikacja, baza danych, serwer www i inne programy uruchamiane przez nas na maszynie.nice– ilość czasu procesora używana przez “miłe” procesy. Poziomniceokresla się w skali od -20 do 19. Im wartość większa, tym proces ma mniejszy priorytet. Domyślna wartość to 0.idle– Na pewno kojarzysz “Proces bezczynności systemu” w WIndowsie 😁. Innymi słowy, jak bardzo nasza maszyna się “obija”.iowait– ilość zmarnowanego czasu przez procesor w oczekiwaniu na operacje wejścia/wyjścia. Duże wartości mogą świadczyć o problemach związanych z dyskiem.irq/softirq– ilość czasu używana przez przerwania.
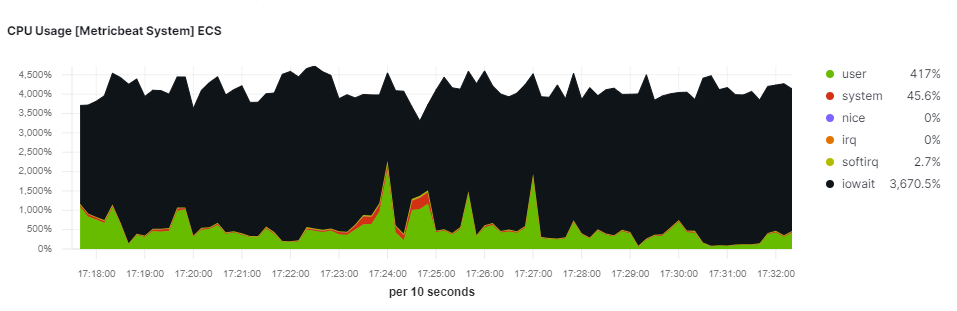
iowait. 1 potężny serwer i Apache Spark. Dyski SSD są szybkie…
Zużycie CPU w dużej mierze zależy od kontekstu. W przypadku przetwarzania danych i analityki zależy nam na jak największej utylizacji procesora. W przypadku Apache Spark pokazałem w tym wpisie. W przypadku cyberbezpieczeństwa, długotrwałe wysokie zużycie CPU może świadczyć o ataku ransomware (szyfrowanie danych) lub ataku DDoS.
RAM
Wycieki pamięci kojarzą nam się z językami typu C/C++, czyli tam, gdzie programista odpowiedzialny jest za alokowanie oraz zwalnianie pamięci. W językach typu Java/C# również jest to możliwe. Garbage Collector nie usunie obiektu jeśli jest do niego referencja.
Z drugiej strony jeśli pamięci jest tak dużo, że się marnuje… to czemu nie utworzyć kolejnej wirtualki? W świecie wirtualizacji powstała metryka o nazwie VM Density, czyli ilość maszyn wirtualnych/kontenerów na pojedynczym serwerze. Jeśli znamy charakterystykę obciążenia maszyn, możemy pokusić się o przydzielenie większej ilości zasobów niż posiada nasz host.
Dyski
Kwestie dysków podzieliłbym na 3 kwestie:
- Miejsce na dysku – im wcześniej wykryjemy problem tym lepiej. Rozproszone bazy danych i systemy plików potrafią mieć sporą zwłokę.
- Wydajność – czyli wykrywanie wąskiego gardła. Wymieniamy dyski na szybsze, a może zmieniamy konfiguracje macierzy/ZFS?
- Awarie – czyli kiedy wysłać kogoś z wiadrem dysków do wymiany.

Sieć
Do kwestii sieci możemy podejść zarówno od strony serwera jak i urządzeń sieciowych. Sieciowcem nie jestem, ale zdaje sobie sprawę jak wymagające jest utrzymanie całej infrastruktury i wykrywanie anomalii w pracy urządzeń, wkładek czy kabli. Z tej perspektywy kluczowa wydaje się agregacja i obsługa wszystkich kluczowych zdarzeń z urządzeń. Niedziałający wiatraczek może eskalować do poważnej awarii.
W przypadku maszyn ,podstawowymi metrykami będą wchodzące/wychodzące bajty i ilość pakietów oraz liczba utraconych pakietów i retransmisji. Ostatnio na własnej skórze doświadczyłem tego, jak istotna jest sprawna sieć w klastrze Elasticsearch. Duży klaster bywa bardzo gadatliwy i niewydajna sieć może znacznie spowolnić zapytania.
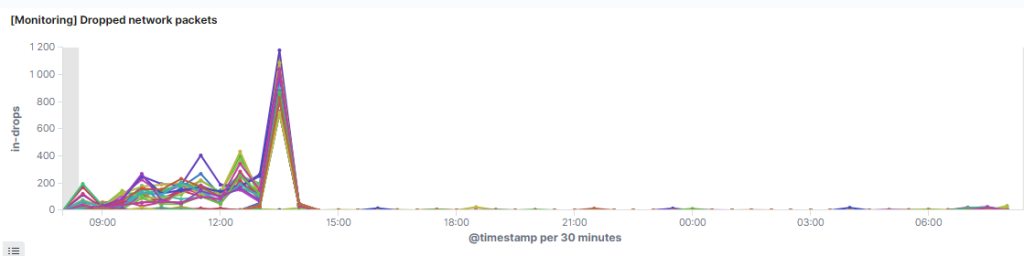
Każda wirtualka/kontener w jakiś sposób komunikuje się z pozostałymi elementami systemu. Gdy jest ich dużo, warto wskazać im konkretne interfejsy sieciowe lub zagregować kilka w logicznie jeden interfejs (LACP).

nloadKoszty
Monitorowanie kosztów chmur publicznych to coś naturalnego. Nikt nie chce obudzić się rano z wyczyszczonym kontem. Nie spotkałem sytuacji w której platforma nie udostępnia narzędzia do analizy i estymacji kosztów.
Nie zmienia to jednak faktu, że skalując jakąś usługę, “skalują” się równiez jej koszty 😄. Koszty monitoringu w chmurze również potrafią swoje kosztować…, a np. Tinder uciął 90% przechodząc z Kinesis na Kafkę.
Uptime i SLA
Awarie zdarzają się najlepszym. Czy jest to chmura publiczna czy lokalna firma informatyczna, każdy klient może dopominać się o swoje prawa według podpisanej umowy. Dobrym pomysłem jest monitorowanie swojego SLA. Bez tego ciężko udowodnić klientowi, że “u mnie działa” 😋.
Zdarzenia i alerty
Oprócz logów i metryk pobieramy również zdarzenia z zewnętrznych systemów. Najłatwiej przytoczyć przykład z działki cyber, czyli wszelkie IDS/IPS, Firewall, DLP, EDR i wszelkie inne narzędzia, których alert jest potencjalnym incydentem.
Dzienniki zdarzeń (Windows) / auditd + /var/log (Linux)
Każdy system operacyjny rządzi się swoimi prawami. W linux’ach logowanie oparte jest głównie na plikach. Możemy się też wspomóc autitd lub Auditbeat. W Windowsach wykorzystywane są dzienniki zdarzeń. Tutaj pomoże nam Winlogbeat oraz Windows Sysinternals (Sysmon). Warto zainteresować się konkretnymi zdarzeniami. Pomóc mogą rekomendacje NSA lub portal
Jaka platforma jest najlepsza?
Oczywiście najlepszą platformą do zbierania logów i metryk jest Elastic Stack, a najwięcej o nim możecie dowiedzieć się z mojego kursu… żartowałem 😁. Jest wiele dobrych rozwiązań. Prometheus i Grafana króluje w kontekście metryk. Loki również zyskuje swoich fanów. Splunk na pewno wyróżnia się pod kątem dojrzałości w cyber, ale uważa się go za drogie rozwiązanie. Elastic trochę już gości na salonach, ale pod kątem działki security jest dość młody. Zabbix to ulubiona platforma wielu administratorów, ale o Observium i Cacti również słyszałem dobre opinie. Po ostatnim incydencie Solarwinds ma trochę mniejszą popularność. W chmurze najbardziej rozpoznawany jest Datadog. Do wyboru do koloru.
